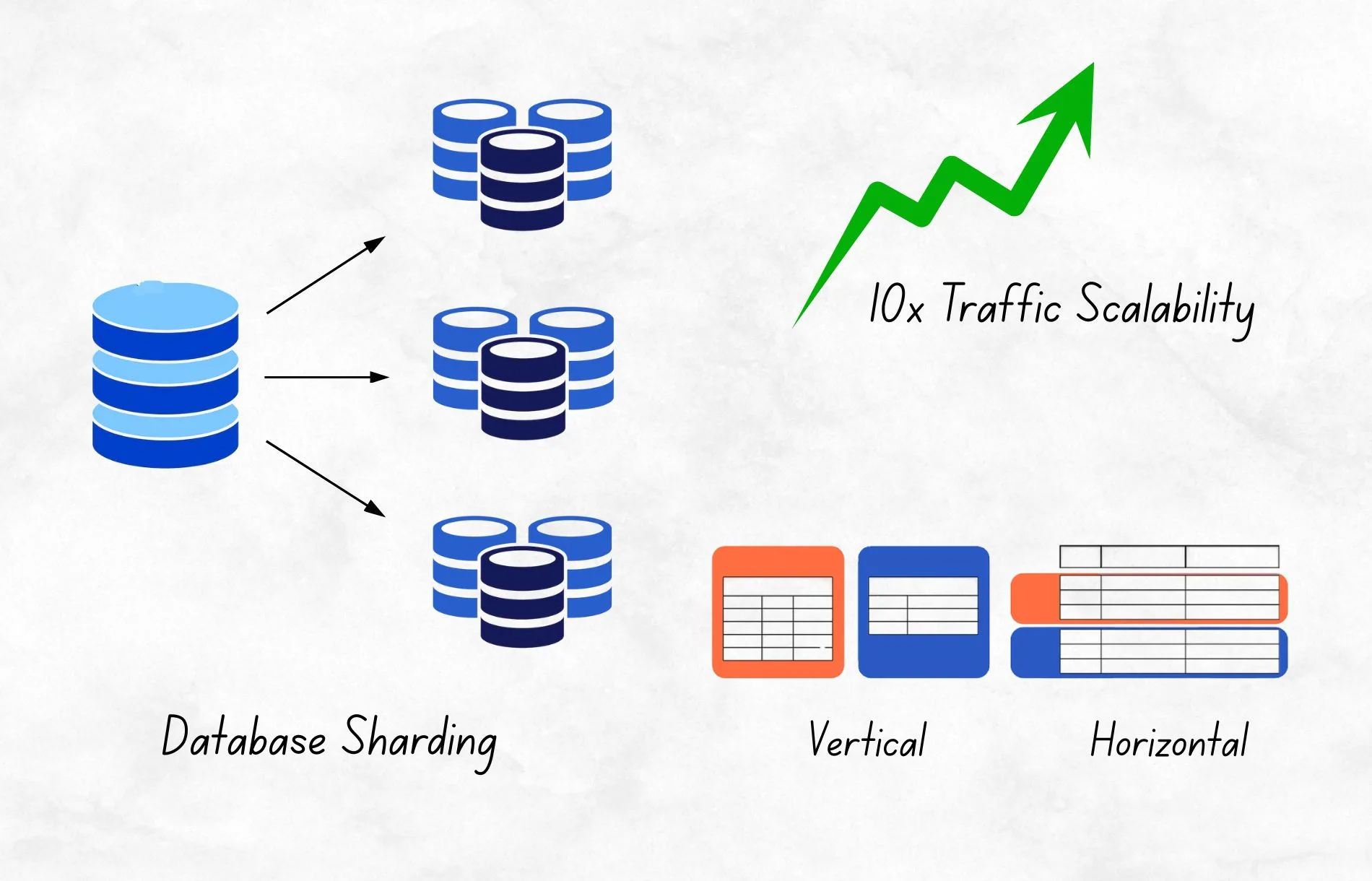
Handling massive amounts of data is a fundamental requirement for today’s most demanding applications, from social media to e-commerce. Among the advanced strategies, database sharding and consistent hashing are two key techniques that enable scalable, reliable data management and drive high-performance distributed systems.
Recently, one of our clients faced frequent slowdowns and downtime during peak traffic hours. By implementing a combination of database sharding and consistent hashing, we helped them scale their system to manage 10x more concurrent traffic, without compromising performance or uptime. Let’s break down how these concepts made it possible.
What is database sharding?
Database sharding is a method of breaking up a large database into smaller, more manageable pieces called shards. Each shard is a separate database that holds a subset of the total data. Instead of having one massive database handling all requests, the system distributes the load across multiple shards.
In our client’s case, we divided their growing user data across multiple shards based on user ID ranges. This ensured that no single database instance was overloaded, resulting in faster page load times and smoother user experience during flash sales and high activity periods.
Why Shard a Database?
Sharding isn’t just a scaling tactic—it’s a strategic approach to distribute data efficiently, reduce load, and ensure your system performs reliably as demand grows.
- Scalability
As data volumes increase, a single database becomes a bottleneck. Sharding allows horizontal scaling by distributing data across multiple servers, ensuring the system can grow seamlessly without compromising performance or user experience. - Performance
Shards contain smaller, more focused datasets. This reduces the time needed to search and retrieve information, enabling faster query execution and improving overall system responsiveness—even under heavy workloads or large-scale operations. - Availability
If one shard goes offline, the rest of the system remains accessible. Sharding improves fault tolerance and minimizes downtime, helping maintain uninterrupted access to services and critical data during hardware failures or maintenance.
Real impact: Before sharding, our client’s system faced query timeouts and API failures during traffic spikes. After distributing data across shards, they saw a 65% reduction in query response time and near-zero downtime, even during high-demand events.
Types of Sharding
- Horizontal Sharding
Horizontal sharding splits data by rows across multiple shards. For instance, user records with IDs 1–1000 might go to Shard A, while 1001–2000 go to Shard B—distributing the load evenly and supporting large-scale user bases. - Vertical Sharding
Vertical sharding separates data by columns or tables. For example, user profile information may be stored on one shard, while transaction records are placed on another—enabling specialization and optimizing performance based on data access patterns.
For our client, horizontal sharding was the right fit. We segmented users based on ID ranges, which aligned well with their read/write access patterns.
What is Consistent Hashing?
When sharding, a big challenge is how to decide which shard stores which piece of data. This is where consistent hashing comes in.
Consistent hashing is a special hashing technique designed to distribute data evenly across shards.
Unlike simple hashing (e.g., key % number_of_shards), which causes major reshuffling when a shard is added or removed, consistent hashing minimizes the number of keys that need to move.
How Does Consistent Hashing Work?
Imagine a circle called a hash ring. Both shards and data items are placed on this ring based on a hash function applied to their identifiers.
Here’s the step-by-step process:
- Hash the shards: Each shard is assigned a position on the ring by hashing its unique identifier (like its IP address or name).
- Hash the data: Each data item (such as a user ID or a key) is also hashed to a point on the ring.
- Assign data to shards: To find which shard stores a particular data item, you move clockwise on the ring from the data’s hash position until you find the first shard. That shard is responsible for that data.
- Adding/removing shards: When a shard joins or leaves, only data items that map between the old shard’s position and the new shard’s position on the ring need to be reassigned, reducing the amount of data that must be moved compared to other hashing methods.
When we added new nodes to accommodate increased traffic, consistent hashing allowed us to integrate them with minimal data movement — reducing the system adjustment time from hours to minutes. This was crucial in keeping services uninterrupted during infrastructure upgrades.
Example of Consistent Hashing
Let’s say we have three shards and four data keys:
Shards: Shard A, Shard B, Shard C
Data keys: “user1”, “user2”, “user3”, “user4”
Assume they are hashed to the following positions on the hash ring (range: 0–100):
| Node/Data | Hashed Position |
| Shard A | 10 |
| Shard B | 40 |
| Shard C | 70 |
| user1 | 5 |
| user2 | 35 |
| user3 | 50 |
| user4 | 80 |
Assignment:
- user1 (5) → First shard clockwise is Shard A (10)
- user2 (35) → First shard clockwise is Shard B (40)
- user3 (50) → First shard clockwise is Shard C (70)
- user4 (80) → No shard at or after 80, so wrap around to Shard A (10)
What happens when a new shard is added?
Suppose Shard D is added at position 60.
- Now user3 (50) which used to map to Shard C (70) will still map to Shard C because it comes after 50 on the ring.
- But user4 (80) will now map to Shard D (60) because 60 is the first shard clockwise from 80 after wrapping around.
- Only the keys that map between old and new shards need to move.
This minimizes the data that must be relocated compared to other hashing strategies like simple modulo hashing.
This exact approach helped our client maintain data balance across new and old shards. It ensured that only a small subset of users were re-routed during scaling, which minimized backend load spikes and stabilized request latency.
How Sharding and Consistent Hashing Work Together
Without a smart data distribution strategy, sharding can become inefficient. Consistent hashing provides an elegant solution by:
- Mapping data to shards dynamically.
- Allowing the system to adapt easily to changes in shard topology.
- Reducing downtime and complexity during scaling.
For example, large-scale systems like Amazon DynamoDB, Cassandra, and Memcached use consistent hashing as a core part of their sharding strategy.
Together, these techniques gave our client’s backend team the flexibility to scale infrastructure proactively, instead of reacting to failures.
Challenges and Considerations
While sharding and consistent hashing are powerful, they come with their own challenges:
- Complexity: Implementing and maintaining a sharded system is more complex than a single database.
- Consistency: Distributed data raises consistency challenges, often requiring careful design of data synchronization.
- Hotspots: Some shards might get more traffic than others, requiring monitoring and possible rebalancing.
For our client, identifying shard hotspots early with monitoring tools helped prevent bottlenecks before they affected end users. This proactive approach was key to sustaining reliable service during high-volume events.
Best Practices for Implementing Sharding and Consistent Hashing
Mastering best practices in sharding and consistent hashing is essential to building scalable, high-performance systems that handle growth smoothly and reliably.
Start With Logical Sharding
Identify natural ways to divide your data, such as by region, customer segment, or time period.
Use Virtual Nodes (VNodes)
Introduce multiple virtual positions for each shard on the hash ring. This helps distribute data more evenly and smooths transitions during scaling.
Monitor Load Distribution
Regularly check for imbalance and redistribute if needed. Tools like Prometheus and Grafana can help track shard metrics.
Prepare for Resharding
Even with consistent hashing, at some scale, you may need to split or merge shards. Build tooling to make this operation smoother.
Frequently Asked Questions:
1. What’s the best way to scale our database to handle growing traffic without impacting performance?
Modern approaches like horizontal scaling, read replicas, and database sharding help manage growing loads without latency. Choosing cloud-native, distributed databases (e.g., Aurora, CockroachDB, or MongoDB Atlas) ensures flexibility as traffic scales.
2. How do we ensure high availability and avoid costly downtime for our applications?
Use a multi-region architecture with failover mechanisms and automated backups. Pair this with real-time monitoring and incident response protocols to detect and fix issues before they affect users.
3. When should we move from a monolithic database to microservices or a distributed data architecture?
When your app’s traffic spikes, release cycles slow down, or teams grow, it’s time to consider decoupling services. Distributed data systems allow faster scaling and fault isolation, supporting business agility.
4. Which database type is best for AI/ML-driven apps or real-time analytics?
NoSQL and time-series databases (like Redis, InfluxDB, or BigQuery) handle unstructured data and real-time insights efficiently. Choose based on speed, scalability, and how well it integrates with your AI/ML stack.
5. How can we future-proof our application architecture to handle scale and performance in the next 3–5 years?
Invest in modular, cloud-native architectures with auto-scaling and serverless components. Focus on observability, resilience engineering, and vendor-agnostic solutions to stay adaptable as demands grow.
The Next Step
Database sharding combined with consistent hashing is a cornerstone of modern distributed systems that need to scale seamlessly and handle massive data loads. Understanding these concepts is essential for architects and developers building scalable applications today. As data continues to grow exponentially, mastering sharding and consistent hashing will be key to designing resilient, high-performance systems.
At Bluetick Consultants Inc, we specialize in architecturing scalable data infrastructures that maintain performance under pressure. For our client, this strategy didn’t just support scale, it delivered stability, faster user experiences, and the confidence to grow without fear of backend breakdowns. That’s the kind of result every high-growth company should aim for.
Struggling to keep up with growing traffic and avoid costly downtime? Let our experts conduct a complimentary database performance review to identify bottlenecks and create a tailored plan that ensures your system grows reliably with your business.