As we continue to advance the capabilities of natural language processing (NLP) systems, one key challenge remains at the forefront of text retrieval systems: how to efficiently split and embed long documents to retain contextual integrity while still enabling fast and effective retrieval. While transformer models have significantly improved the quality of text embeddings, they still face limitations when it comes to understanding long texts, especially when split into smaller chunks. This often results in the loss of important contextual information, which can degrade the quality of retrieval tasks.
In this post, we’ll dive into an exciting new approach to this problem: Late Chunking. Based on a novel paper by researchers at Jina AI, this method aims to overcome the limitations of naive chunking strategies by leveraging long-context embedding models in a way that allows the embeddings to retain contextual relevance across chunks. We’ll explain how Late Chunking works, its advantages, and its impact on a wide range of retrieval tasks. We will also discuss practical examples and show how you can implement this approach in your own projects.
Understanding the Problem: Chunking and Its Challenges
Before we dive into the solution, let’s break down the problem of chunking in text embeddings.
Why Chunking?
In many NLP use cases, long documents need to be split into smaller chunks. This is especially the case with dense vector-based retrieval systems that work by representing documents as embeddings (dense vectors). These embeddings allow the retrieval system to compare documents based on similarity, typically using cosine similarity. However, because transformer models often have input size limitations, such as a maximum token length, documents that exceed this size need to be split into smaller chunks to be processed by the model.
The Problem with Naive Chunking
Naive chunking methods typically involve splitting a long document into smaller, fixed-size chunks—often at sentence or paragraph boundaries. However, this approach introduces several problems:
- Loss of Context: When a document is split into smaller chunks, the transformer model processes each chunk independently. This means that long-distance semantic dependencies are often lost. For instance, if one chunk refers to a concept introduced in another chunk, the model might not be able to link these references accurately.
- Over-Compression: If the chunks are too short, the model’s embeddings might “over-compress” the information, losing important nuances and meaning that span multiple chunks.
- Suboptimal Retrieval: This lack of contextual coherence in chunk embeddings directly impacts the quality of retrieval systems, which rely on embedding similarity to rank documents for relevance.

Late Chunking: A Novel Approach
Late Chunking, as introduced in the paper, seeks to solve these issues by processing the full context of a document before performing chunking. The key idea is to embed the entire document in one go, retaining the full context, and only apply chunking after the embedding process, during mean pooling. This allows chunk embeddings to retain the context and semantic relationships that were present across the entire document.
How Does Late Chunking Work?
Here’s a breakdown of how Late Chunking works:
- Full Document Encoding: The entire document is first passed through a long-context transformer model. This step encodes all tokens in the document while retaining the full semantic context between them.
- Chunking After Encoding: Instead of splitting the document before embedding, Late Chunking applies chunking after the document has been fully embedded. The document is then split into chunks at predefined boundaries (such as sentence or paragraph boundaries), and each chunk receives an embedding by pooling the token embeddings of the chunk’s tokens.
- Mean Pooling on Chunks: The final step involves applying mean pooling on the token embeddings within each chunk. This ensures that the chunk embeddings contain contextual information from the entire document and are not isolated from the broader context.
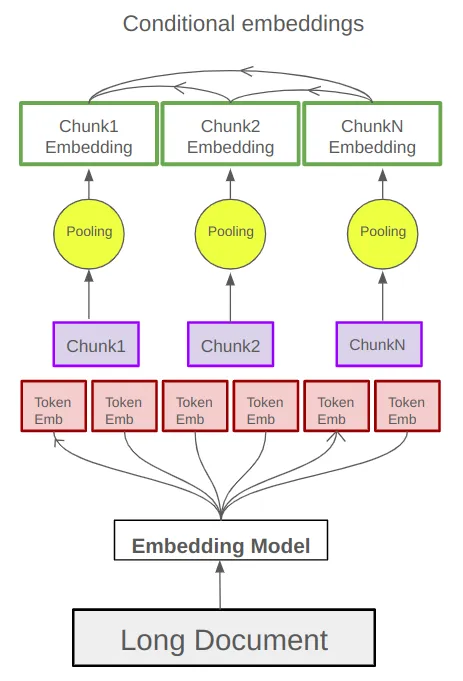
By applying this method, Late Chunking ensures that each chunk’s embedding captures relevant contextual information from the document, improving the quality of retrieval tasks and making the embeddings much more reliable in terms of relevance.
Key Advantages of Late Chunking
- Context Preservation: The most significant advantage of Late Chunking is its ability to preserve context across chunks. Since the whole document is processed before chunking, the model can understand relationships between different sections of the text that may span multiple chunks.
- Improved Retrieval Accuracy: As demonstrated in the research, Late Chunking consistently outperforms naive chunking in various retrieval benchmarks, leading to higher relevance and better retrieval accuracy.
- No Need for Extra Training: Late Chunking doesn’t require additional training beyond the pre-trained embedding model, making it easier to implement in existing systems.
- General Applicability: Late Chunking can be applied to any embedding model that uses mean pooling and chunking, making it a versatile solution across different systems and architectures.
Example: Comparing Naive Chunking vs Late Chunking
Let’s take a look at a concrete example to see how Late Chunking works in practice. Consider the following excerpt from a Wikipedia article about Berlin:
"Berlin is the capital and largest city of Germany, both by area and by population. Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. The city is also one of the states of Germany, and is the third smallest state in the country in terms of area."
Naive Chunking: When chunking this document naively, each chunk would be processed independently, and embeddings would be generated for individual sentences. The references in sentences like “its” or “the city” that point to “Berlin” might not be accurately captured because the model doesn’t have full visibility of the context in other chunks.
Late Chunking: With Late Chunking, the full document is processed first, preserving the relationship between all parts of the text. Therefore, when it comes time to generate the embeddings for each chunk, the embedding for the chunk containing “its” or “the city” would correctly reflect the context that points back to “Berlin.”
Performance Comparison: As shown in the original paper, Late Chunking yields much higher cosine similarity scores when comparing chunks because the method retains the reference across different chunks. In retrieval tasks, this improvement is reflected in normalized Discounted Cumulative Gain (nDCG@10) scores. Evaluation results show that Late Chunking significantly outperforms Naive Chunking:
Models: jina-embeddings-v2-small (J2s), jina-embeddings-v3(J3), nomic-embed-text-v1 (Nom).
Code Implementation:
Required packages needed:
!pip install transformers==4.43.4
Importing Libraries
from transformers import AutoModel
from transformers import AutoTokenizer
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
Sentence-Based Text Chunking Using Tokenizer
This function splits a long piece of text into sentence-like chunks by detecting periods (“.”) and whitespace between them using the tokenizer.
def chunk_by_sentences(input_text: str, tokenizer: callable):
inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)
punctuation_mark_id = tokenizer.convert_tokens_to_ids('.')
sep_id = tokenizer.convert_tokens_to_ids('[SEP]')
token_offsets = inputs['offset_mapping'][0]
token_ids = inputs['input_ids'][0]
chunk_positions = [
(i, int(start + 1))
for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))
if token_id == punctuation_mark_id
and (
token_offsets[i + 1][0] - token_offsets[i][1] > 0
or token_ids[i + 1] == sep_id
)
]
chunks = [
input_text[x[1] : y[1]]
for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
span_annotations = [
(x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
return chunks, span_annotations
Chunking Using Jina Tokenization API
import requests
def chunk_by_tokenizer_api(input_text: str, tokenizer: callable):
# Define the API endpoint and payload
url = 'https://tokenize.jina.ai/'
payload = {
"content": input_text,
"return_chunks": "true",
"max_chunk_length": "1024"
}
# Make the API request
response = requests.post(url, json=payload)
response_data = response.json()
# Extract chunks and positions from the response
chunks = response_data.get("chunks", [])
chunk_positions = response_data.get("chunk_positions", [])
# Adjust chunk positions to match the input format
span_annotations = [(start, end) for start, end in chunk_positions]
return chunks, span_annotations
Example Input and Sentence Chunking Execution
input_text = "Berlin is the capital and largest city of Germany, both by area and by population. Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. The city is also one of the states of Germany, and is the third smallest state in the country in terms of area."
# determine chunks
chunks, span_annotations = chunk_by_sentences(input_text, tokenizer)
print('Chunks:\n- "' + '"\n- "'.join(chunks) + '"')
OUTPUT
Chunks:
– “Berlin is the capital and largest city of Germany, both by area and by population.”
– ” Its more than 3.85 million inhabitants make it the European Union’s most populous city, as measured by population within city limits.”
– ” The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.”
Late Chunking Function for Context-Aware Pooling
Performs “late” chunking”—applies sentence-level pooling after generating the full-context output from the model. It uses token spans to average embeddings.
def late_chunking(
model_output: 'BatchEncoding', span_annotation: list, max_length=None, num_tokens =1024
):
token_embeddings = model_output[0]
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation):
if (
max_length is not None
): # remove annotations which go beyond the max-length of the model
annotations = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start < (max_length - 1) ] pooled_embeddings = [ embeddings[start:end].sum(dim=0) / (end - start) for start, end in annotations if (end - start) >= 1
]
pooled_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputs
Traditional Chunking (Encode Chunks Individually)
Embeds each chunk individually using traditional encode method (no cross-sentence context).
# chunk before
embeddings_traditional_chunking = model.encode(chunks)
# chunk afterwards (context-sensitive chunked pooling)
inputs = tokenizer(input_text, return_tensors='pt')
model_output = model(**inputs)
embeddings = late_chunking(model_output, [span_annotations])[0]
Cosine Similarity Comparison
Calculates and compares cosine similarities between the word “Berlin” and each chunk, using:
- new_embedding from context-aware (late chunking)
- trad_embeddings from traditional method
import numpy as np
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
berlin_embedding = model.encode('Berlin')
for chunk, new_embedding, trad_embeddings in zip(chunks, embeddings, embeddings_traditional_chunking):
print(f'similarity_new("Lara", "{chunk}"):', cos_sim(berlin_embedding, new_embedding))
print(f'similarity_trad("Lara", "{chunk}"):', cos_sim(berlin_embedding, trad_embeddings))
OUTPUT
similarity_new(“Berlin”, “Berlin is the capital and largest city of Germany, both by area and by population.”): 0.849546
similarity_trad(“Berlin”, “Berlin is the capital and largest city of Germany, both by area and by population.”): 0.8486219
similarity_new(“Berlin”, ” Its more than 3.85 million inhabitants make it the European Union’s most populous city, as measured by population within city limits.”): 0.82489026
similarity_trad(“Berlin”, ” Its more than 3.85 million inhabitants make it the European Union’s most populous city, as measured by population within city limits.”): 0.70843387
similarity_new(“Berlin”, ” The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.”): 0.8498009
similarity_trad(“Berlin”, ” The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.”): 0.75345534
Real-World Impact: Application in Retrieval Systems
Late Chunking significantly enhances retrieval systems, especially in information retrieval tasks where context matters a lot. This method can be applied across various industries and domains:
- Search Engines: Improving the relevance of search results by accurately capturing context from large documents.
- Legal and Research Domains: In legal research, where precise and context-aware document retrieval is crucial, Late Chunking can help retrieve relevant cases, articles, and precedents based on context, not just keyword matching.
- Customer Support and Chatbots: When a chatbot retrieves information from a knowledge base, Late Chunking helps ensure that the context across different chunks is understood, leading to more accurate responses.
Frequently asked questions:
1. What does it take to integrate RAG into our existing tech stack?
You’ll need an internal knowledge base, a vector database, and connectors to your LLM. Most modern stacks (AWS, Azure, GCP) support this with minimal disruption if the data is already structured or well-documented.
2. Can RAG or AI apps be deployed securely within our private cloud or on-prem?
Yes RAG pipelines and LLMs can be containerized and deployed behind your firewall or in VPCs. Many organizations use open-source or fine-tuned models for full data control and compliance.
3. What kind of AI use cases have worked for companies like ours?
Use cases vary, but common wins include intelligent automation in operations, predictive analytics for planning, and conversational AI for service. Industry-specific models can drive sharper outcomes with less experimentation.
4. How do we ensure data privacy and compliance when deploying AI solutions?
Start by working with partners who follow ISO, SOC2, or GDPR standards. Clear data governance policies, audit trails, and model transparency are key to managing risk and building trust internally and externally.
5. What’s the ROI we can realistically expect from investing in AI?
Most companies see ROI through cost savings, faster delivery, or revenue uplift within 6–12 months. The key is targeting high-impact, low-friction use cases first then scaling based on results.
Conclusion
Late Chunking is a game-changing method for improving text embeddings in retrieval tasks. By ensuring that context is preserved across chunks, it leads to more accurate and relevant results, which is critical in applications that rely on retrieval systems. Whether you’re working with long documents or handling chunking in embedding models, implementing Late Chunking can significantly boost the performance of your NLP applications.
References:
Michael Gunther, Isabelle Mohr, Daniel James Williams, Bo Wang, Han Xiao,
“Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models,”arXiv, 2024.
Jina AI, “Late Chunking: Efficient DocumentRetrieval,”https://github.com/jina-ai/late-chunking
“Late Chunking: Embedding First Chunk Later — Long-Context Retrieval in RAG Applications”, Medium, 2024.