
Introduction
Meta’s latest AI model, Llama 3, has sparked intrigue and excitement with its promising improvements
over its predecessor, Llama 2. Integrated into popular Meta applications like Instagram and
Facebook, Llama 3 brings forth enhanced capabilities, particularly through its chatbot feature. This
article delves into the advancements of Llama 3 and how it stacks up against Llama 2.
Performance Enhancements:
Llama 3 boasts significant performance
enhancements compared to Llama 2. With 8 billion parameters in its 8B versions, Llama 3 has
undergone intensive training using custom-built 24,000 GPU clusters on over 15T token of data , also
with context length of 8192 tokens, supports 30 languages. This substantial boost in performance
addresses previous criticisms and positions Llama 3 as a formidable contender in the AI landscape.
Where as Llama 2 7b comes up with less performance than Llama 3 8b ,as it was trained on 2 trillion
tokens, also with context length of 4096 tokens, support only 20 languages.
Metrics Comparison:
In the realm of AI language models, the metrics of Mean Multi-Layer Update (MMLU), Average Reasoning
Capabilities (ARC), and Dataset for Reasoning Over Paragraphs (DROP) serve as vital benchmarks for
evaluating performance and proficiency. Llama 3 marks a paradigm shift in this regard, outclassing
its predecessor, Llama 2, across these key metrics.
Llama 3’s expansion to configurations of up to 70 billion parameters translates into a deeper
understanding of language nuances, reflected in its superior MMLU scores. This increase in
complexity enables Llama 3 to grasp and process multi-layered information more effectively than ever
before.
Furthermore, Llama 3’s training on a bespoke 24,000 GPU cluster has proven instrumental in enhancing
its reasoning capabilities, as evidenced by its impressive ARC scores. The investment in robust
training infrastructure has undoubtedly propelled Llama 3 ahead of Llama 2 in terms of comprehension
and logical reasoning.
When it comes to tackling complex datasets like DROP, Llama 3 emerges as the undisputed champion,
showcasing unmatched proficiency in reasoning over paragraphs. Its ability to navigate through
intricate textual data sets with precision underscores its superiority over Llama 2 in terms of
knowledge acquisition and retention.
In conclusion, the metric comparison
between Llama 3 and Llama 2 highlights a clear trajectory of progress and advancement. With superior
scores across MMLU, ARC, and DROP, Llama 3 reaffirms its status as a game-changer in the landscape
of AI language models, setting new standards for efficiency, accuracy, and domain-specific
proficiency.
Data Training:
Llama 3’s training regimen marks a significant leap forward. Trained on over 15 trillion tokens
sourced from public data, Llama 3’s dataset dwarfs that of Llama 2, enabling it to respond to a
broader range of queries. Additionally, Llama 3 incorporates a robust collection of non-English data
spanning over 30 languages, enhancing its accessibility and utility for global users.
As said earlier,Llama 2 is trained on over only 2 Trillion token of public data.Even it only support
20 languages.
Enhanced Scalability and Deployment Capabilities
Scalability and ease of deployment are paramount considerations in maximizing the practical utility
of any AI model. Llama 3 represents a significant leap forward in this regard, introducing a range
of improvements to enhance versatility and accessibility for researchers and developers.
The model’s redesigned architecture prioritizes efficient scaling across diverse hardware
configurations, laying the foundation for seamless deployment across a spectrum of platforms and
devices. This optimization not only expands the model’s reach but also ensures optimal performance
across varying computing environments, catering to the evolving demands of AI solutions.
Moreover, leveraging the open-source ethos of Llama 2, Meta AI adopts an inclusive approach for Llama
3, fostering a collaborative ecosystem where a wider community of researchers and developers can
contribute, customize, and deploy the model in their projects. This democratization of access not
only fuels innovation but also accelerates the adoption of Llama 3 as a preferred solution in the AI
landscape.
In essence, the evolution from Llama 2 to Llama 3 signifies Meta AI’s commitment to advancing
language models while prioritizing scalability and deployment ease. With its enhanced capabilities,
Llama 3 is poised to redefine the landscape of AI applications, offering unparalleled performance
and utility across diverse use cases.
Model Efficiency and Accuracy
Llama 3 marks a significant step forward in the evolution of Meta AI’s language models, showcasing
notable enhancements in both efficiency and accuracy over its predecessor, Llama 2.
One of the standout improvements is the expansion in the model’s parameters, with Llama 3 offering
configurations of up to 70 billion parameters. This increase not only signifies a leap in the
model’s complexity but also its ability to understand and generate language with greater precision.
The training of Llama 3 on a
bespoke 24,000 GPU cluster has evidently paid dividends, enabling it to outperform Llama 2 across a
range of metrics, including MMLU, ARC, and DROP. These metrics are crucial indicators of a model’s
performance, with higher scores reflecting an ability to better comprehend and respond to complex
queries.
Comparison Table(BENCHMARKS):
| Benchmark | Llama-3-8B | Llama-2-7B | Improvement |
|---|---|---|---|
| MMLU 5-shot | 68.4 | 34.1 | 100.6% |
| QPQA 0-shot | 34.2 | 21.7 | 57.6% |
| Human-Eval 0-shot | 62.2 | 7.9 | 687.3% |
| GSM-8K | 79.6 | 25.7 | 209.7% |
| MATH 4-shot,CoT | 30.0 | 3.8 | 689.5% |
(Source: Data obtained from https://llama.meta.com/ website)
Unveiling Insights with Titanic Dataset: A Comparative Analysis of Llama-2 and Llama-3.
In the realm of natural language processing (NLP), advancements in language models have enabled
various applications, from chatbots to text summarization. Recently, two powerful models, Llama-2
and Llama-3, exhibit remarkable capabilities in understanding and generating human-like text. In
this, we’ll delve into how these models can be leveraged to interactively explore the famous Titanic
dataset using a Streamlit application.
Titanic Dataset: A Classic Example
The Titanic dataset is a classic example often used in data science tutorials and competitions. It
contains information about passengers aboard the RMS Titanic, including demographics, ticket class,
fare, and survival status. This dataset serves as an excellent playground for demonstrating the
capabilities of language models in analyzing structured data.
Setting Up the Environment
Before we dive into the code, ensure
you have the necessary dependencies installed, including Streamlit, Seaborn, and the LangChain
library. Once everything is set up, we can begin creating our Streamlit app.
The Experiment
Let’s dive into the code and set up our experiment environment.
LLAMA-2-7B Code
import seaborn as sns
import streamlit as st
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain_community.llms import Ollama
#Call ollama model
llm = Ollama(model="llama2:latest")
st.title("Interactive Titanic Dataset Exploration with Llama-2-7b Model")
#load seaborns internal dataset
dataframe = sns.load_dataset("titanic")
#Display top 5 rows
st.write(dataframe.head(5))
# Call pandas dataframe agent
agent = create_pandas_dataframe_agent(
llm,
dataframe,
verbose=True,handle_parsing_errors=True
)
prompt = st.text_input("Enter your prompt:")
if st.button("Generate"):
if prompt:
with st.spinner("Generating response..."):
response = agent.invoke(prompt)
st.write(response["output"])
LLAMA-3-8B Code
import seaborn as sns
import streamlit as st
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain_community.llms import Ollama
#Call ollama model
llm = Ollama(model="llama3:latest")
st.title("Interactive Titanic Dataset Exploration with Llama-3-8b Model")
#load seaborns internal dataset
dataframe = sns.load_dataset("titanic")
#Display top 5 rows
st.write(dataframe.head(5))
# Call pandas dataframe agent
agent = create_pandas_dataframe_agent(
llm,
dataframe,
verbose=True,handle_parsing_errors=True
)
prompt = st.text_input("Enter your prompt:")
if st.button("Generate"):
if prompt:
with st.spinner("Generating response..."):
response = agent.invoke(prompt)
st.write(response["output"])
OBSERVATIONS:
In the exploration of the Titanic dataset with both Llama-2 and Llama-3 models, several questions
were posed to each model to gain insights into their capabilities. From the responses generated and
the time taken for inference, valuable insights about each model emerged.
Question Section:
When querying both Llama-2 and Llama-3 models with the question “How many people died and how many
people survived?”
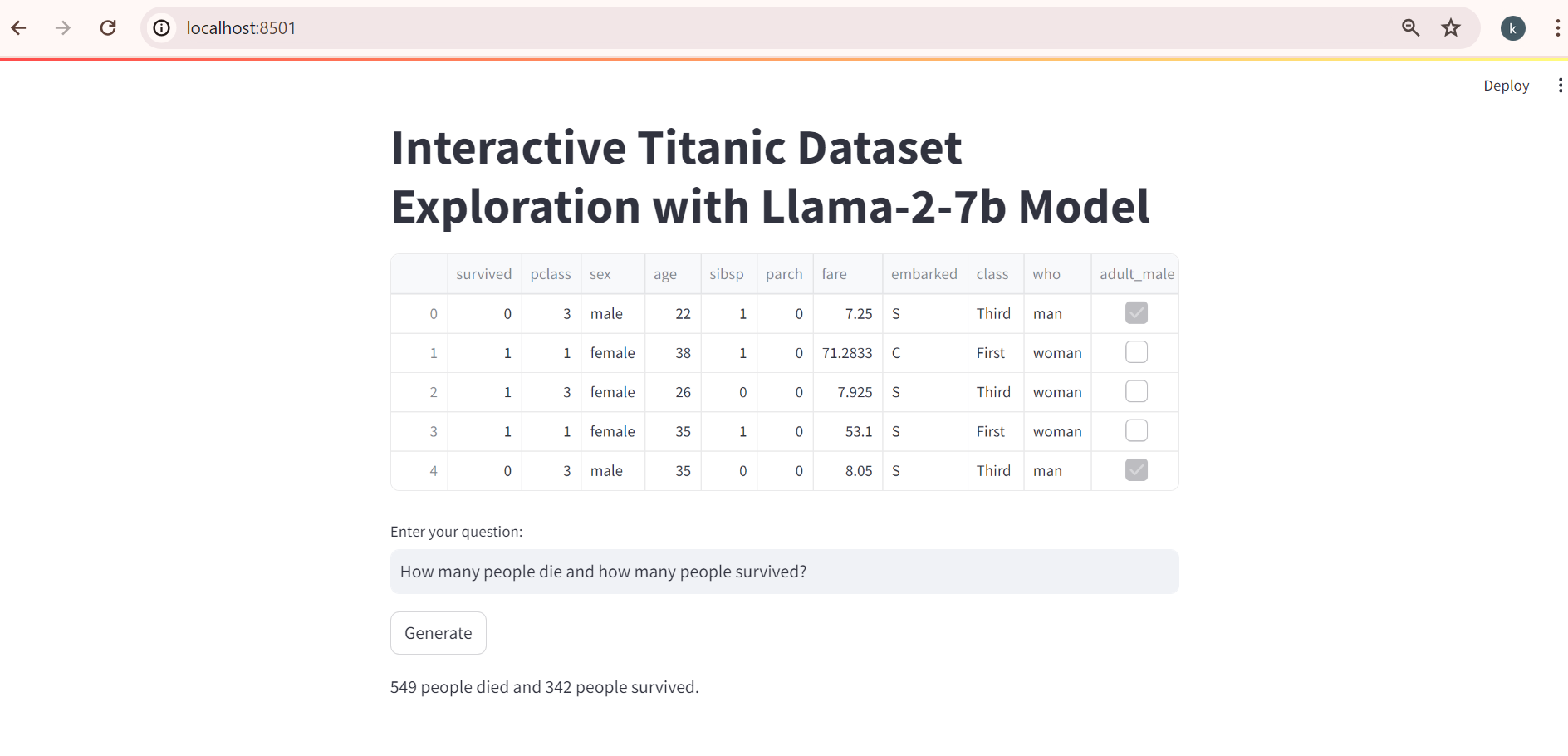
Llama-2-7b Response :
The Streamlit application executes the Llama 2 code upon activation, allowing users to pose
questions. Subsequently, the generated responses are displayed below for further examination.
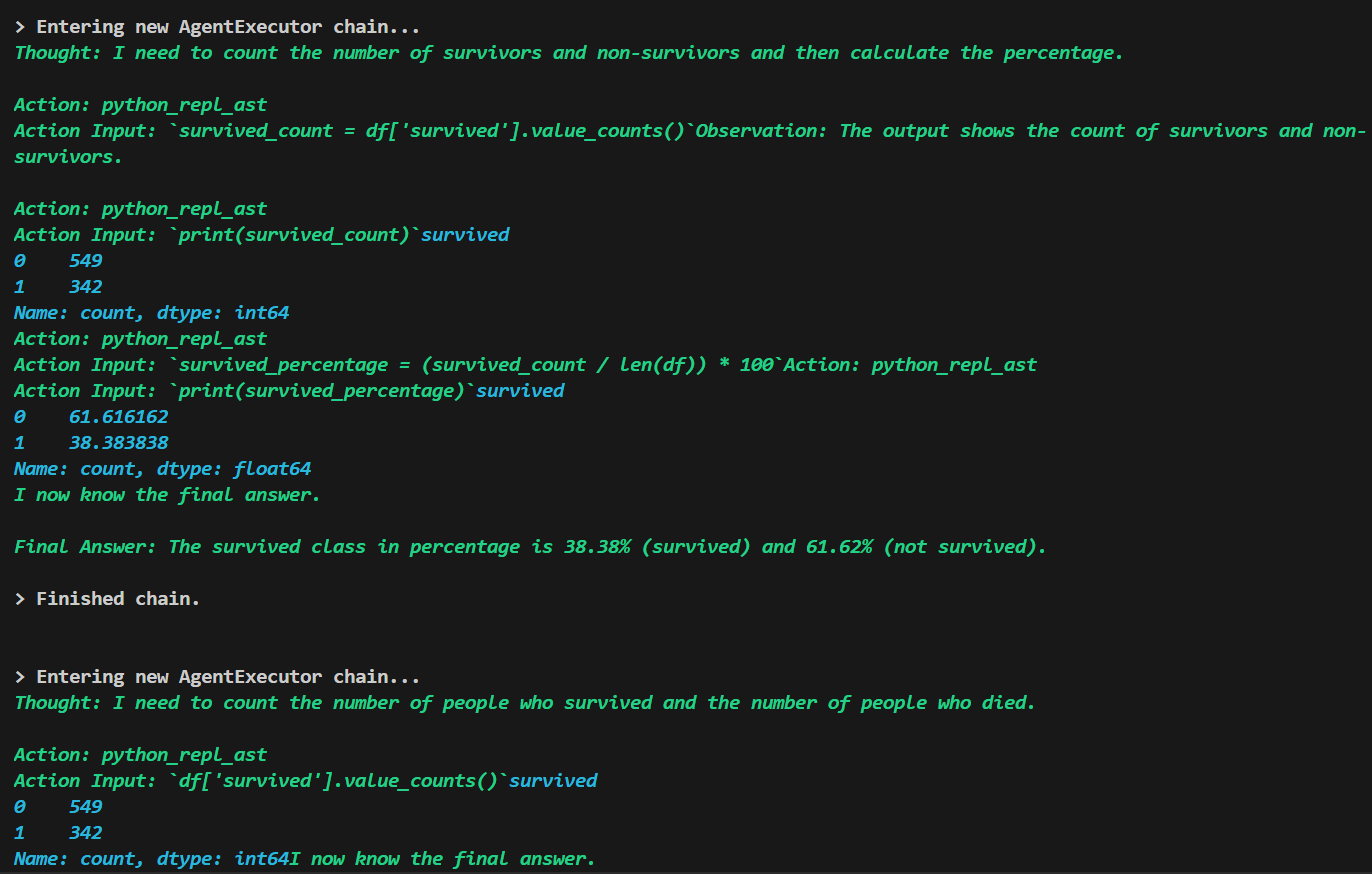
Generation process of chain:
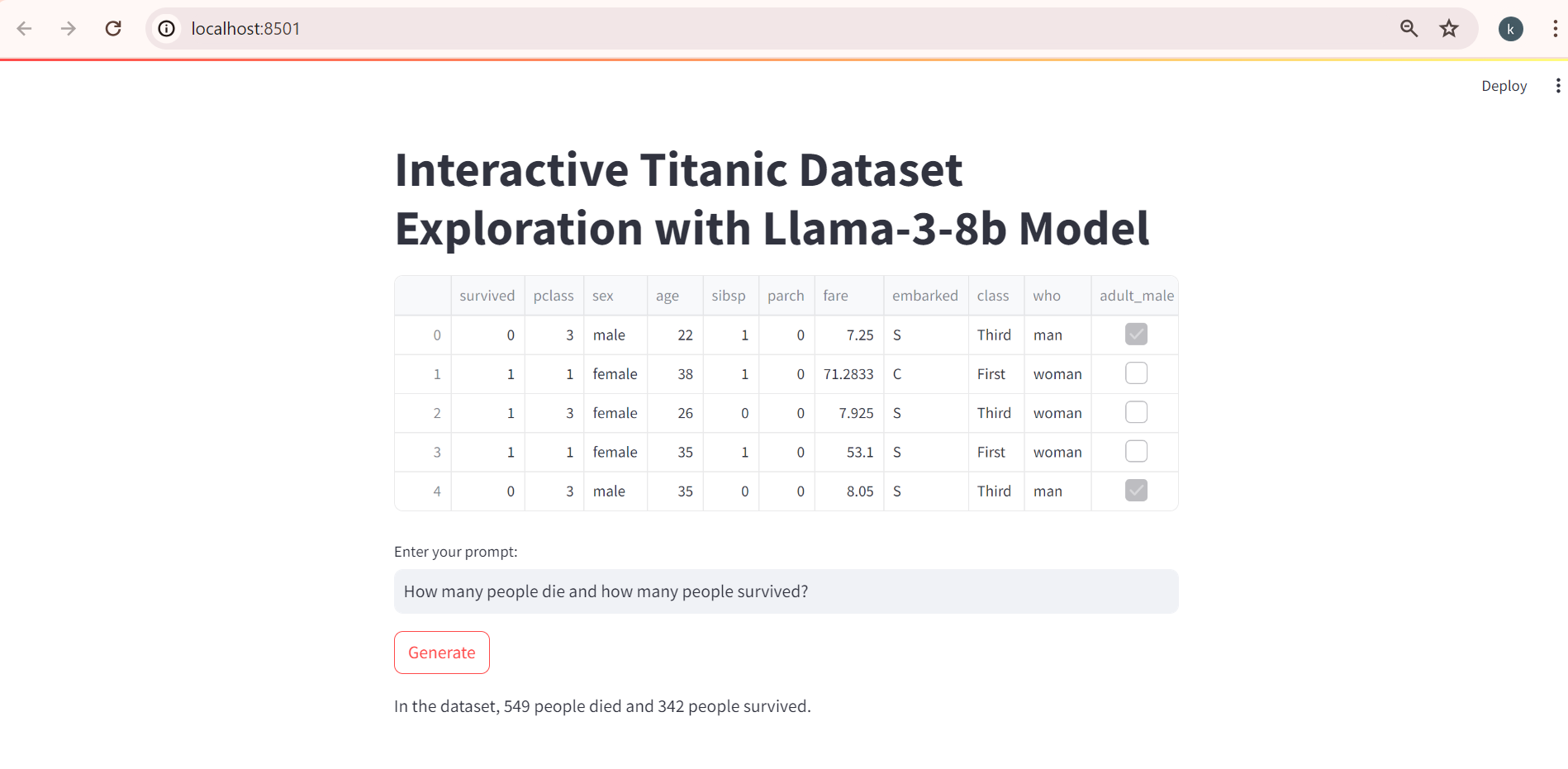
Llama-3-8b Response:
The Streamlit application executes the Llama 3 code upon activation, allowing users to pose
questions. Subsequently, the generated responses are displayed below for further examination.
Generation process of chain:
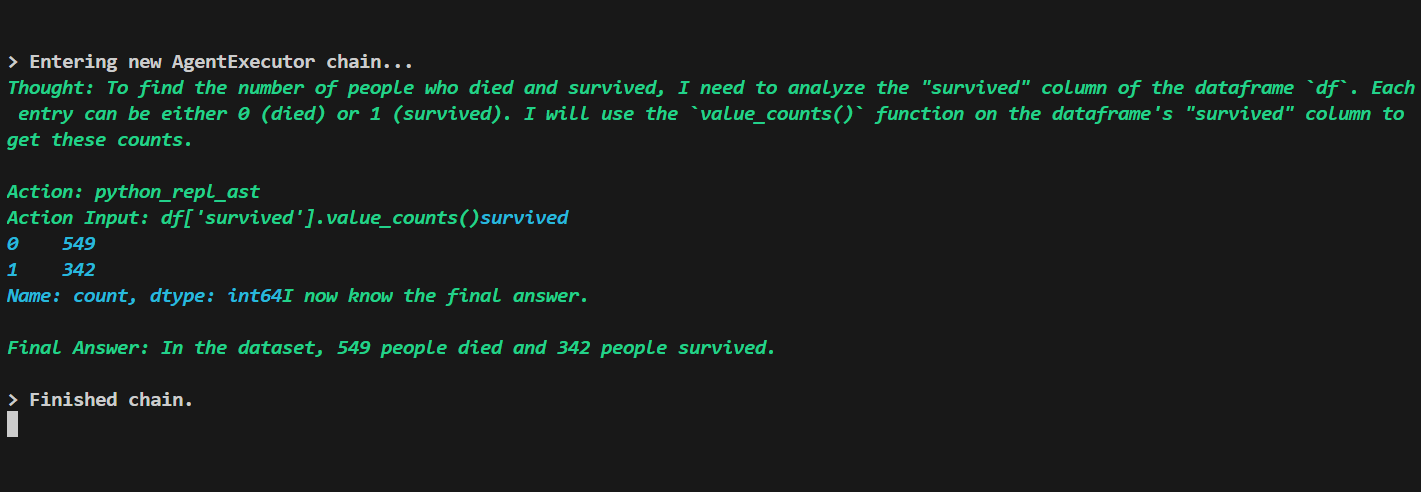
INFERENCE FROM CHAIN OUTPUT:
Upon analyzing the chain output, it becomes evident that Llama-3-8b reaches a conclusion with fewer
iterations compared to Llama-2-7b. This observation suggests that Llama 3 may possess a more
efficient inference process, potentially indicating superior computational efficiency or
optimization. While this observation provides initial insights into the models’ performance, further
analysis and experimentation are necessary to comprehensively understand their respective strengths
and limitations.
Question-Response Comparison Table: Llama-2-7b vs. Llama-3-8b
than others?
survive than others. Specifically, passengers from Cherbourg had the highest survival
rate.
survive than others. Specifically, passengers who embarked from Cherbourg had the
highest survival rate,followed by Queenstown and then Southampton.
the highest survival rates, whereas the Llama 2 model suggested only one.
siblings/spouses and those without?
and those without is approximately 0.121 (0.466 – 0.345)
sibling/spouse and those without any siblings/spouses is approximately 19.05%.
between passengers with and without siblings/spouses, enhancing clarity. Llama-2’s
response lacks specificity in detailing the difference.
the Titanic, and how does it relate to survival rates?
Titanic is 806. The survival rates for passengers with and without siblings/spouses and
parents/children vary, but in general, passengers with more siblings/spouses and
parents/children tend to have higher survival rates. The overall survival rate for all
passengers is approximately 38.38%.
aboard. Analysis of the relationship between family size and survival demonstrated a
slight trend: passengers with larger family sizes slightly more often survived than
those with smaller families. On average, survivors had a family size of approximately
0.939 compared to 0.883 for those who did not survive.
correlation with survival rates, enhancing understanding. Llama-2 lacks detailed
insights into family sizes and survival correlations.
total number of passengers and the average fare, and how does it compare to the cost of
constructing the ship?
which is a small fraction of the cost of constructing the ship, which was around 7.5
million dollars in 1912.
approximately 28,693.95,insignificantly less than the cost of constructing the ship,
which was about 28,693.95,is significantly less than the cost of constructing the
ship,which was about 7.5 million. This indicates that the ticket sales alone were far
from covering the construction cost of the Titanic.
construction cost, highlighting financial implications. Llama-2’s response lacks depth
in comparing revenue to construction cost.
Choosing the Best: Deciding Between Options
Based on author observation , Llama 3 emerges as a clear winner, showcasing remarkable advancements
over Llama 2 across various dimensions. Meta’s commitment to enhancing AI capabilities is evident in
Llama 3’s superior performance, broader language support, and seamless integration into popular
applications. With its enhanced usability and robust features, Llama 3 cements Meta’s position in
the forefront of AI innovation.