
Introduction
In recent years, the capabilities of large language models (LLMs) have rapidly expanded, allowing them to perform complex tasks such as content generation, question answering, and even code generation. However, despite their impressive abilities, LLMs are largely considered stateless—meaning that each call to a model starts fresh without any memory of past interactions.
To bridge this gap and create truly intelligent agents, memory systems need to be integrated into LLMs. These memory systems allow the agent to remember, learn from past experiences, and adapt over time. In this blog post, we’ll explore four key types of memory that are crucial to building intelligent agents: Working Memory, Episodic Memory, Semantic Memory, and Procedural Memory.
By combining these different types of memory, we can create agents capable of persistent learning and dynamic reasoning, moving beyond basic static text generation into a more human-like system of interaction.
What Are the Four Types of Memory in LLM-based Agents?
1. Working Memory: The Agent’s Active Context
In human cognition, working memory is responsible for temporarily holding and processing information that is actively being used. For a chatbot or language model agent, this means maintaining the current conversation context and real-time interaction state.
In a stateless LLM, every prompt is treated independently, without any awareness of previous interactions. But with working memory, the agent can remember prior messages, the roles in the conversation, the goals, and the ongoing task at hand.
Example: If a user asks for their name in the middle of a conversation, the LLM can use its working memory to recall and respond accurately without needing to be explicitly told again.
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
# Initialize LLM model
llm = ChatOpenAI(temperature=0.7, model="gpt-4",openai_api_key="")
# Define System Prompt
system_prompt = SystemMessage("You are a helpful AI Assistant. Answer the User's queries succinctly in one sentence.")
# Start Storage for Historical Message History
messages = [system_prompt]
while True:
# Get User's Message
user_message = HumanMessage(input("\nUser: "))
if user_message.content.lower() == "exit":
break
else:
# Extend Messages List With User Message
messages.append(user_message)
# Pass Entire Message Sequence to LLM to Generate Response
response = llm.invoke(messages)
print("\nAI Message: ", response.content)
# Add AI's Response to Message List
messages.append(response)
# Displaying the conversation history stored in working memory
for i in range(len(messages)):
print(f"\nMessage {i+1} - {messages[i].type.upper()}: ", messages[i].content) Output
User: Hello!
AI Message: Hello! How can I assist you today?
User: Can you tell my name?
AI Message: As an AI, I don't have access to personal data about individuals unless it has been shared with me in the course of our conversation.
User: No worries, my name is keerthi
AI Message: Nice to meet you, Keerthi! How can I assist you today?
User: what is my name?
AI Message: Your name is Keerthi.
2. Episodic Memory: Learning from Past Experiences
Episodic memory is the ability to recall specific past events or episodes. In an AI agent, this allows the system to learn from previous interactions and reflect on past mistakes or successes.
For instance, the agent might analyze a conversation it had earlier to understand what worked well or identify what it should avoid in the future. This memory type is crucial for improving the agent’s responses over time. Instead of only relying on raw input-output pairs, episodic memory lets the system extract patterns from past conversations to provide better, more context-aware responses.
Example: If a user asks a question about a topic they’ve previously discussed, the agent can recall past conversations and provide a more informed and nuanced response.
The idea is that, as the AI interacts with a user, it recalls the context of previous conversations to give more relevant, personalized responses. To achieve this, we’ll combine FAISS (Facebook AI Similarity Search) with OpenAI’s embeddings API to store and retrieve conversational memories based on similarity.
Setting Up the FAISS Index
We begin by initializing the FAISS index to store the conversation vectors. Each conversation is converted into an embedding (a numerical representation) using OpenAI’s embeddings API. These vectors are then indexed by FAISS, enabling fast retrieval based on similarity.
import openai
import faiss
import numpy as np
from typing import List, Dict
# Set your OpenAI API Key
openai.api_key = ''
# Initialize FAISS Index
dimension = 1536 # For OpenAI's text-embedding-ada-002 model
index = faiss.IndexFlatL2(dimension) # L2 distance index
conversation_memory = []
# Define helper function to get OpenAI embeddings
def get_openai_embedding(text):
# Use the Embedding API to generate the embeddings
response = openai.embeddings.create(
model="text-embedding-ada-002", # Use OpenAI's embedding model
input=text
)
# Return the embedding from the response
return np.array(response.data[0].embedding, dtype='float32')
Adding Conversations to Memory
A method to convert text into embeddings, we can store them in the FAISS index and also keep track of the metadata, such as tags and summaries, that will help contextualize the conversation.
def add_to_memory(conversation: str, context_tags: List[str], summary: str, what_worked: str, what_to_avoid: str):
embedding = get_openai_embedding(conversation)
embedding = embedding.reshape(1, -1) # Reshape to ensure it's a 2D array with shape (1, dimension)
faiss.normalize_L2(embedding) # Normalize the vector for FAISS
index.add(embedding) # Add to FAISS index
conversation_memory.append({
"conversation": conversation,
"context_tags": context_tags,
"conversation_summary": summary,
"what_worked": what_worked,
"what_to_avoid": what_to_avoid
})
Episodic Recall: Searching for Similar Conversations
Episodic recall searches for similar past conversations by converting user queries into embeddings and comparing them with stored memories using FAISS. The system then updates the prompt based on the retrieved memory, adjusting its responses according to what worked well in previous interactions.
# Define the function for episodic recall
def episodic_recall(query: str) -> Dict:
query_embedding = get_openai_embedding(query)
query_embedding = query_embedding.reshape(1, -1) # Ensure it has the correct shape (1, dimension)
faiss.normalize_L2(query_embedding) # Normalize the query embedding
# Perform FAISS search
_, indices = index.search(query_embedding, k=1) # Search for most similar memory
best_match = indices[0][0]
# Return the corresponding memory from the stored conversation
return conversation_memory[best_match]
# Example function to simulate adding a memory
add_to_memory(
"HUMAN: What's my name? AI: You said your name is Adam.",
context_tags=["personal_information", "name_recall"],
summary="Recalled the user's name after being informed in the conversation.",
what_worked="Storing and recalling the user's name effectively within the session.",
what_to_avoid="N/A"
)
# Update the system prompt based on retrieved memory
def update_system_prompt(user_input: str, query: str) -> str:
# Retrieve the most relevant memory from FAISS
memory = episodic_recall(query)
# Build a system prompt incorporating the memory
system_prompt = f"""
You are a helpful AI Assistant. Answer the user's questions to the best of your ability.
You recall similar conversations with the user, here are the details:
Current Conversation Match: {memory['conversation']}
Previous Conversations: {query}
What has worked well: {memory['what_worked']}
What to avoid: {memory['what_to_avoid']}
Use these memories as context for your response to the user.
"""
return system_prompt
# Example of using the updated system prompt
user_input = "What's my name?"
query = "HUMAN: What's my name?"
updated_prompt = update_system_prompt(user_input, query)
print(updated_prompt)Output
User: What's my name?
AI: Based on our past conversation, What's my name?
User: What's my name?
AI: Based on our past conversation, What's my name?
User: My name is keerthi.
AI: Based on our past conversation, My name is keerthi.
User: What's my name?
AI: Based on our past conversation, your name is keerthi.
3. Semantic Memory: Knowledge Representation and Factual Grounding
While episodic memory helps the agent learn from experience, semantic memory provides the foundational knowledge that the agent uses to answer questions and make decisions. This type of memory stores facts, concepts, and relationships about the world, which are essential for reasoning and context-based interactions.
In LLM-based systems, semantic memory could be external knowledge from databases, documentation, or even prior training. With technologies like Retrieval-Augmented Generation (RAG), semantic memory can be dynamically queried to supplement an agent’s responses with factual data, improving its accuracy and relevance.
Example: When asked a question about the capital of a country, the agent doesn’t need to rely on its immediate context or previous conversations—it can retrieve this information directly from its semantic memory.
# 3 Semantic Memory
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
import openai
# Assuming we have a list of knowledge documents
documents = [
"The Eiffel Tower is in Paris, France, and is one of the most famous landmarks in the world.",
"Mount Everest is located in the Himalayas and is the highest mountain on Earth.",
"The capital of France is Paris."
]
# Initialize OpenAI Embeddings
embeddings = OpenAIEmbeddings(api_key ="")
# Create a FAISS index for semantic memory
semantic_memory = FAISS.from_texts(documents, embeddings)
# Query the semantic memory for relevant information
query = "What is the capital of France?"
result = semantic_memory.similarity_search(query, k=1)
print(f"Semantic Memory Answer: {result[0].page_content}")
Output
User query: What is the capital of France?
Semantic Memory Answer: The capital of France is Paris.
4. Procedural Memory: “How-To” Knowledge and Task Execution
Procedural memory stores the rules and processes that govern how an agent behaves. For a language agent, this memory encompasses the operational foundation—from the underlying model weights (which determine how the agent processes language) to the framework code that defines the agent’s interaction patterns and decision-making strategies.
Unlike other forms of memory, procedural memory is focused on how to perform tasks. It guides the agent’s actions, from generating text to accessing memory stores to making real-time decisions. Updates to procedural memory occur through fine-tuning of the model weights or altering the core system code.
Example: A chatbot might remember how to process specific types of input, such as interpreting user feedback, or how to interact with a database in a structured way to generate accurate responses.
import openai
openai.api_key = "" # Replace with your actual OpenAI API key
# Define initial procedural memory (rules)
procedural_memory = {
"greet_user": "Greet the user warmly and ask how you can assist.",
"answer_factual_question": "Provide a concise and accurate answer to the user's factual questions.",
"ask_for_clarification": "If the question is unclear, politely ask the user to clarify.",
"follow_up": "After providing an answer, ask if the user needs further assistance."
}
# Function to update procedural memory dynamically based on user feedback
def update_procedural_memory(new_feedback):
# Add new feedback or updates to procedural memory
procedural_memory["user_feedback"] = new_feedback
print("\nProcedural Memory Updated:")
print("\n".join([f"{key}: {value}" for key, value in procedural_memory.items()]))
# Function to use OpenAI API to generate responses based on procedural memory
def generate_openai_response(task, context=None):
# Construct prompt for OpenAI based on task and procedural memory
# Construct the messages with the user input and procedural memory
messages = [
{"role": "developer", "content": f"You are an AI assistant. The user is asking: '{task}'. Here are the current procedural rules:\n{procedural_memory}\nRespond according to these guidelines."},
]
if context:
messages.append({"role": "system", "content": f"Context: {context}"})
# Add the user's question/message
messages.append({"role": "user", "content": task})
# Use OpenAI API to generate a response
# Request the completion
completion = openai.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=100
)
return completion.choices[0].message.content
# Function to simulate procedural task execution (task performance) and learning
def procedural_task_execution(task, user_feedback=None, context=None):
print(f"\nPerforming Task: {task}")
# Generate a response using OpenAI based on task and procedural memory
task_response = generate_openai_response(task, context)
print(f"Task Response: {task_response}")
# If feedback is provided, update the procedural memory with the new rule
if user_feedback:
update_procedural_memory(user_feedback)
# Example simulation: Performing a task and learning
procedural_task_execution("Greet the user and ask how they would like assistance.")
# Simulate user feedback on performance (learning)
user_feedback = "When greeting, offer further assistance politely without being too formal."
procedural_task_execution("Greet the user and ask how they would like assistance.", user_feedback)Output
Performing Task: Greet the user and ask how they would like assistance.
Task Response: Hello! How can I assist you today?
Performing Task: Greet the user and ask how they would like assistance.
Task Response: Hello! How can I assist you today?
Procedural Memory Updated:
greet_user: Greet the user warmly and ask how you can assist.
answer_factual_question: Provide a concise and accurate answer to the user's factual questions.
ask_for_clarification: If the question is unclear, politely ask the user to clarify.
follow_up: After providing an answer, ask if the user needs further assistance.
user_feedback: When greeting, offer further assistance politely without being too formal.
Performing Task: Greet the user and ask how they would like assistance.
Task Response: Hello! How can I assist you today? If you'd like, I can help you with something specific.
Code
Visualizing the Interaction of Memory Systems
The following diagram provides a clear representation of how different memory systems work together within a language model-based intelligent agent. It illustrates the flow of information from working memory through episodic, semantic, and procedural memory, as well as the decision-making process that drives agent actions.
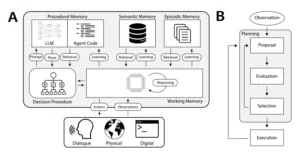
How These Memory Systems Work Together
The true power of memory systems in language agents lies in how these different types of memory integrate and inform each other. Each memory type plays a specific role:
- Working Memory stores immediate context and enables real-time interaction.
- Episodic Memory allows for learning from prior experiences, making the agent more adaptive.
- Semantic Memory ensures factual grounding, improving the agent’s ability to reason and respond accurately.
- Procedural Memory ensures that the agent can effectively execute tasks and learn new strategies for interaction.
Example: In a customer service chatbot, the working memory holds the current conversation context, while episodic memory recalls past issues the user faced, semantic memory provides the factual product knowledge, and procedural memory defines how the agent navigates various service processes.
Towards Truly Intelligent Agents
Integrating memory systems into language model agents transforms them from stateless tools into adaptive, context-aware, and human-like collaborators. By leveraging working memory, episodic memory, semantic memory, and procedural memory, we create agents that not only generate responses but also remember, reason, and evolve.
This layered memory architecture is a significant step toward building artificial general intelligence (AGI)-like behavior within bounded domains. The synergy between these memory types allows agents to continuously improve, personalize interactions, and handle increasingly complex tasks.
Reference:
- Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, Thomas L. Griffiths, Cognitive Architectures for Language Agents, Princeton University, 2024.
- ALucek, Agentic Memory GitHub Repository, 2024.
Frequently Asked Questions on AI Cognitive Architectures and Memory Systems
What is cognitive architecture, and why is it important for LLM-based agents?
A cognitive architecture is a blueprint for building agents that mimic human-like reasoning, memory, and learning. It provides a structured way to combine LLMs with symbolic reasoning, memory retrieval, and decision-making—making agents more autonomous and goal-directed.
How can LLM agents be given memory?
LLM agents can have memory by integrating vector stores, knowledge graphs, or episodic memory modules. This allows them to recall past interactions, learn from them, and maintain context across long sessions.
What are the main types of memory systems for AI agents?
Short-term memory for immediate context (the context window) and long-term memory for persistent knowledge (an external database).
What’s the difference between reactive agents and cognitive agents?
Reactive agents respond to prompts without internal memory or planning, while cognitive agents reason, plan, and remember. Cognitive agents, built with architectures like ACT-R or using tools like LangGraph or AutoGPT, simulate human-like thinking for more complex workflows.
How can LLM agents retrieve relevant past information during a task?
They use semantic search across a vector database to retrieve contextually similar data. This retrieval-augmented generation helps the LLM maintain coherence and relevance over extended interactions.
AI Automation and AI Integration Services
At Bluetick Consultants Inc., we build the infrastructure that powers real-world AI applications. From GenAI feature engineering to automation pipelines and enterprise-grade integrations, we help companies deploy AI that works reliably, securely, and at scale.
AI Feature Development: Custom LLM integrations, computer vision modules, and predictive analytics built for your specific business requirements. We architect scalable AI features with advanced memory systems and real-time learning capabilities that integrate seamlessly into your products and platforms.
AI Automation: Intelligent process automation using AI to handle document processing, customer service workflows, and operational tasks. Our solutions are built with fault-tolerance and adaptability, ensuring they evolve with your business needs.
AI Integration: Seamless API connections between your existing systems and leading AI platforms including OpenAI, Claude, and custom-trained models. We specialize in enterprise-grade deployments ensuring security, compliance, and performance across cloud, hybrid, and on-premise environments.
With years of hands-on experience across industries, Bluetick has become a trusted partner for companies looking to move beyond AI prototypes into production-grade systems. Our team works closely with tech leaders to align every AI initiative with business goals, technical constraints, and long-term scalability.
Want to turn your vision into a working AI system?
Fill out your project needs in the form below. Our AI architects will review and respond within 2 hours.