
The goal of Named Entity Recognition is to locate and classify named entities in a sequence. The
named
entities are pre-defined categories chosen according to the use case such as names of people,
organizations,
places, codes, time notations, monetary values, etc. Essentially, NER aims to assign a class to each
token
(usually a single word) in a sequence. Because of this, NER is also referred to as token
classification.

Model developing Process
For this we are using pre-trained models from simple transformers which build over Hugging face
Library.
Implemetation Process
The process of performing Named Entity Recognition in Simple Transformers does not deviate from the
standard
pattern.
- Initialize a NERModel
- Train the model with train_model()
- Evaluate the model with eval_model()
- Make predictions on (unlabelled) data with predict()
Supported Model Types using simple transformers
1 . ALBERT = albert
2 . BERT = bert
3 . BERTweet = bertweet
4 . BigBird = bigbird
5 . CamemBERT = camembert
6 . DeBERTa = deberta
7 . DeBERTa = deberta
8 . DeBERTaV2 = deberta-v2
9 . DistilBERT = distilbert
10 . ELECTRA = electra
11 . HerBERT = herbert
12 . LayoutLM = layoutlm
13 . Longformer = longformer
14 . MobileBERT = mobilebert
15 . MPNet = mpnet
16 . RoBERTa = roberta
17 . SqueezeBert = squeezebert
18 . XLM = xlm
19 . XLM-RoBERTa = xlmroberta
20 . XLNet = xlnet
The above models completely uses concept encoders and decoders
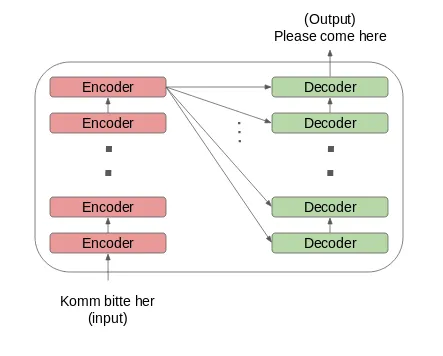
Data Formats
A DataFrame containing the 3 columns sentence_id, words, labels. Each value in words will have a
corresponding
labels value. The sentence_id determines which words belong to a given sentence. I.e. the words from
the same
sequence should be assigned the same unique sentence_id.
Named entity recognition depends on the lables . Model can develop in different lable format here we
are using
an couple of lablels [‘O’, ‘B-geo’, ‘B-gpe’, ‘B-per’, ‘I-geo’, ‘B-org’, ‘I-org’, ‘B-tim’, ‘B-art’,
‘I-art’,
‘I-per’, ‘I-gpe’, ‘I-tim’, ‘B-nat’, ‘B-eve’, ‘I-eve’, ‘I-nat’]
Explanation of the labels
- O = Outside of a named entity
- B-MIS = Beginning of a miscellaneous entity right after another miscellaneous entity
- I-MIS = Miscellaneous entity
- B-PER = Beginning of a person’s name right after another person’s name
- I-PER = Person’s name
- B-ORG = Beginning of an organisation right after another organisation
- I-ORG = Organisation
- B-LOC = Beginning of a location right after another location
- I-LOC = Location
Model used for Named entity recognition
Bert-Based-cased
- Arguments.num_train_epochs = 3
- Arguments.train_batch_size = 32
- Arguments.eval_batch_size = 32
- Arguments.learning_rate = 4e-5
- Arguments.max_seq_length = 128
- Arguments.adam_epsilon = 1e-8
- Arguments.do_lower_case = True
- Arguments.n_gpu = 1
- Arguments.overwrite_output_dir = True
Follow technical report.docx file for complete explanation about models used and for dataset.