



Converting color images to black and white is quite easy using the OpenCV framework,but for converting black and white images to color we need to take a different approach. We need to add colors to black and white pixels using Deep Learning Neural Networks. Let's first look at how the color information is represented in gray scale images and digital images.
Gray scale image means the value of each pixel represents only the intensity information of the light. Such images commonly display only the darkest black to the brightest white. The image carries only black, white, and gray colors, in which gray has multiple levels.Each pixel typically consists of 8 bits(1byte) for gray scale images and there are 256 possible grayscale colors.

Color images have three different channels called RGB. Each pixel intensity was represented by three channels. Each color image has 24 bits/pixel, which means 8 bits for each of the three color bands(RGB).There are 16 million colors possible.
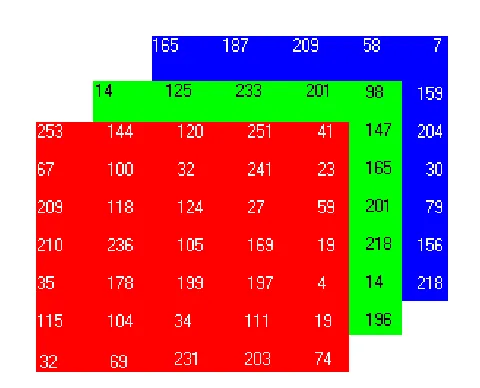
Black and White Image to Color Image
We trained a neural network which converts this grayscale image to the colored one. It needs to learn to map this single value to a three channel image. For this purpose we used a concept called LAB space where we figured out the lightness scale of each pixel and mapped them correspondent A and B channels.
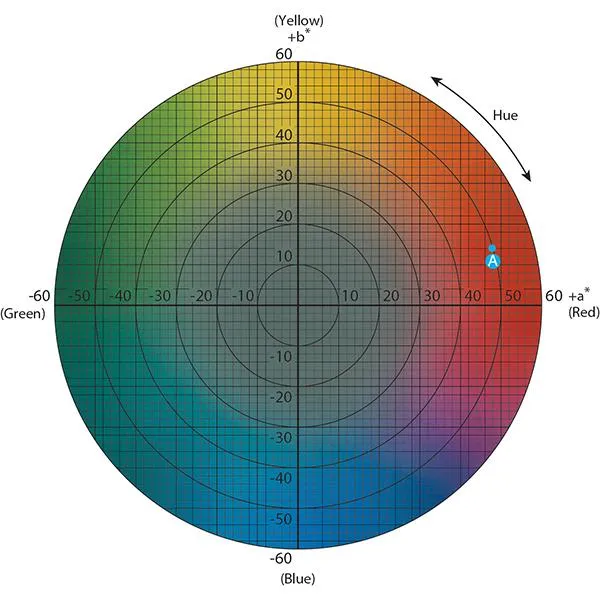
LAB color space
- Lab is an another color space same like RGB where
- L channel = Lightness
- A channel = from green-red
- B channel = from Yellow-blue
Here the grayscale images are in only the L channel. Hence,we find lab color space is more convenient for our problem. we develop a Neural network where it should map our lightness of pixel intensity to their A and B channel. But even though we map A and B channels we used to get only 2 channels but color images need 3 different channels so the third channel is nothing but the original image.So our input value is lightness of each pixel and our neural network should predict A and B channels and add original input. Using OpenCV we can convert them into RGB format.
Technologies used
- Neural Networks
- Open CV
- Tensorflow
- Statistics for Normalization
For this purpose we used a pre-trained neural network which was already trained on Imagenet grayscale dataset.It uses a simple convolutional neural network architecture. As explained above, we take the L channel image and learn to predict a and b channels. Combining the prediction and input would give us the colorized image which looks like a Lab color space image.
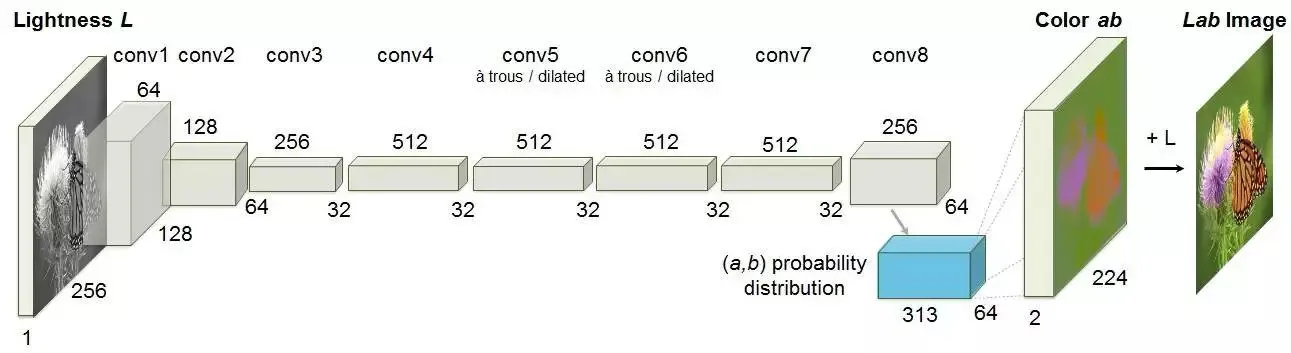
After collecting pretrained weights and using tensorflow and opencv we convert predicted lab space images into RGB format.Hence the Neural network trained on 1000 different greyscale images we got 91.29 % accuracy for our results. Some results are

For videos we divide each frame individually and send it to the neural network and finally we add each predicted frame and convert them back to video. Some results using videos.






