



An entity can be a word or series of words that consistently refer to the same thing. Every detected entity is classified into a prelabelled category. For example, a NER model might detect the word "London" in a text and classify it as a 'Geography'.
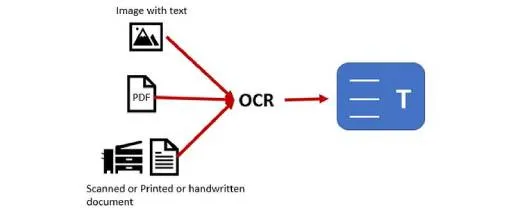
But we need to find the entities from the images. So for this purpose, we need to extract text from the images, so for extracting text we are a technique called OCR.
What is Optimal character recognition(OCR)?
OCR stands for Optical Character Recognition. It is widespread technology to recognize text inside images, such as scanned documents and photos. OCR is used to convert any kind of image containing text like(typed handwritten or printed) into machine-readable text format.
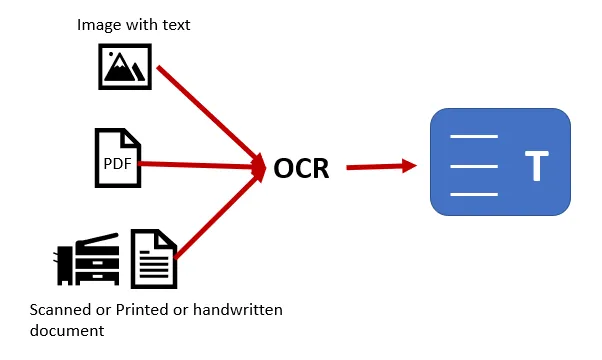
For extracting the text we are using open-source software called tesseract which can be implemented using the Pytesseract package.
Techniques used
- Open CV
- Spacy
- Nltk
- OCR
- Regex
- Pandas
How does Pytesseract work?
Pytesseract detects the images in five different stages where we can collect complete text step by step
Step: 1 -> detect complete page
Step: 2 -> detect individual blocks of the image
Step : 3 -> detect paragraphs
Step: 4 -> detect Line
Step: 5 -> detect words
For detecting entities, we collected individual words from images using step 5 and created a rectangle box on the top of each word using geometric transformations

Same procedure we applied for entire data and collected individual words and saved it in a CSV file.
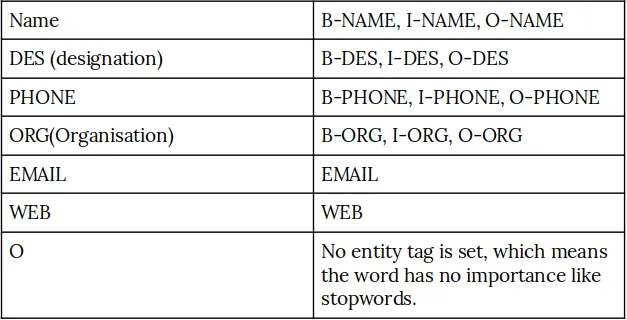
For detecting the entities we need class labels for each word, so for creating custom entity recognition on images we used a technique called BIO, where B - Token begins an entity, I - Token is inside an entity, O - Token is outside an entity. Using five different labels we made unstructured data into a structured format. Class labels we used to train the models are,
Now for training the custom entity recognition, we selected a spacy pre-trained model, so we convert the data into a spacy format like complete image data and its corresponding words and labels into dictionary type, This process, we applied for entire data and divide the data into the training part and the testing part. For training purposes, we used 50 epochs where at the end of the training we got 94% accuracy for the model, 91% precision, and 90.6% recall. We test around 20 images using our trained model and check the results,

But we got predictions based on the labels we gave for each word while training using the BOI concept, so we find a solution to collect the index position, left and right positions which we get from Pytesseract, for the predicted word and if any word matched BOI format with the same name we can add those detected labels.
Finally, after adding their index positions it works well to detect entities from the images.

Few Predicted Images :








