









Introduction
Bridging Language and Data in the Enterprise Sphere: In the realm of enterprise data management, SQL databases have long stood as the backbone, housing vast quantities of invaluable information. As enterprises increasingly lean on business intelligence (BI) tools to extract insights from these data repositories, the quest for more intuitive and accessible querying methods gains momentum. The emerging solution? Leveraging Large Language Models (LLMs) to interact with SQL databases using natural language. This innovative approach, powered by the latest advancements in NLP, promises to transform our interaction with data. However, as groundbreaking as it sounds, integrating LLMs into SQL querying is riddled with challenges, making it a complex and intriguing endeavor.
The Challenges of LLMs for SQL Query Generation:
While LLMs possess an impressive grasp of SQL, enabling them to construct complex queries, several non-trivial issues arise in actual implementations:
- The Hallucination Dilemma: A significant hurdle is the tendency of LLMs to 'hallucinate' - creating fictitious tables or fields, or generating SQL queries that are incompatible with the actual database structure. This misalignment between the model's output and database reality poses a major obstacle in ensuring the validity and reliability of the queries generated.
- The Context Window Constraint: LLMs operate within a context window, a limitation on the amount of text they can process at a given time. This becomes particularly problematic in the context of SQL databases, which often contain extensive and complex schemas. The challenge lies in effectively grounding the LLM in the database's reality without overwhelming its context window.
- Error Handling and Unpredictability:Despite their capabilities, LLMs are not infallible. The SQL queries they generate may occasionally be erroneous or yield unexpected results. This inconsistency raises critical questions about dependability and error mitigation strategies. Do we accept these limitations or devise mechanisms to counter them?
The High Level Solution
Mimicking Human Expertise for Enhanced LLM Performance: To effectively address the challenges faced by Large Language Models (LLMs) in generating SQL queries, we can draw inspiration from the strategies employed by human data analysts. By emulating the steps a data analyst takes in querying SQL databases, we can guide LLMs towards more accurate and efficient query generation. Let's explore these human-inspired strategies:
- Sample Queries and Schema Familiarization: Like a data analyst who first familiarizes themselves with the database by executing sample queries and reviewing table schemas, an LLM can benefit from a similar approach. This involves exposing the LLM to the structure and a snapshot of the data it will be working with. By understanding the actual makeup of the database - its tables, fields, and typical data entries - the LLM can generate queries that are more aligned with the reality of the database's structure.
- Dealing with Information Overload and Context Window Limitation: Data analysts typically don't analyze all data at once; they often start with a subset, examining top rows or summary statistics. This approach can be mimicked to overcome the LLM's context window limitations. Instead of feeding the LLM with the entire database, we can provide it with a distilled version, highlighting key aspects of the data. This selective exposure ensures the LLM remains 'grounded' in the database's reality without overloading its processing capabilities.
- Error Handling and Iterative Learning: Just as a data analyst doesn't abandon their task after encountering an error, LLMs should also be equipped to learn from mistakes. When an LLM generates an incorrect SQL query, mechanisms can be implemented to analyze the error, provide feedback to the model, and iteratively improve the query. This process not only refines the LLM's query-generation capabilities but also enhances its ability to adapt to different databases and query requirements.
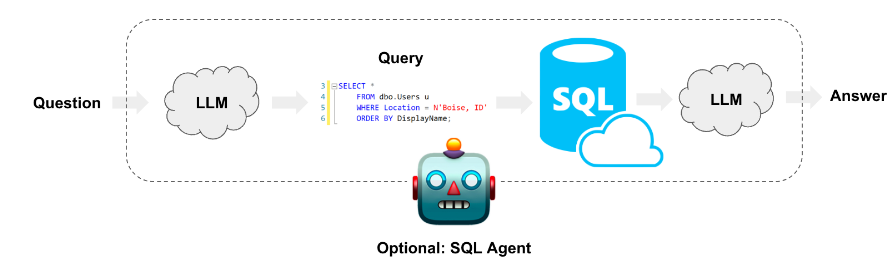
The Path Forward:
By adopting these human-inspired approaches, we can significantly improve the effectiveness of LLMs in SQL query generation. These strategies not only address the specific challenges of hallucination, context window constraints, and error handling but also pave the way for LLMs to operate more autonomously and reliably in complex data environments. The journey towards integrating LLMs into SQL querying, thus, becomes a blend of technological innovation and cognitive emulation, holding promise for a new era of data interaction.
Langchain Agents
LangChain has a SQL Agent which provides a more flexible way of interacting with SQL Databases than a chain. The main advantages of using the SQL Agent are:
- It can answer questions based on the databases' schema as well as on the databases' content (like describing a specific table).
- It can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
- It can query the database as many times as needed to answer the user question.
To initialize the agent we'll use the create_sql_agent constructor. This agent uses the SQLDatabaseToolkit which contains tools to:
Coding with Agent
Github Link - here
Step 1: Creating a Database Schema
To simulate a real-world scenario, we will create a simple e-commerce database schema encompassing five entities: customer, seller, product, cart, and payment. Each entity will have its own attributes, and we will establish foreign key relationships to introduce complexity. This schema will serve as our testing ground for the LLM's SQL query generation.
import sqlite3
db_path = '/content/sample.db'
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
script='''
CREATE TABLE Cart (
Cart_id TEXT PRIMARY KEY NOT NULL
);
CREATE TABLE Customer (
Customer_id TEXT PRIMARY KEY NOT NULL,
c_pass TEXT NOT NULL,
Name TEXT NOT NULL,
Address TEXT NOT NULL,
Pincode INTEGER NOT NULL,
Phone_number_s INTEGER NOT NULL,
Cart_id TEXT NOT NULL,
FOREIGN KEY(Cart_id) REFERENCES Cart(Cart_id)
);
CREATE TABLE Seller (
Seller_id TEXT PRIMARY KEY NOT NULL,
s_pass TEXT NOT NULL,
Name TEXT NOT NULL,
Address TEXT NOT NULL
);
CREATE TABLE Seller_Phone_num (
Phone_num INTEGER NOT NULL,
Seller_id TEXT NOT NULL,
PRIMARY KEY (Phone_num, Seller_id),
FOREIGN KEY (Seller_id) REFERENCES Seller(Seller_id) ON DELETE CASCADE
);
CREATE TABLE Payment (
payment_id TEXT PRIMARY KEY NOT NULL,
payment_date DATE NOT NULL,
Payment_type TEXT NOT NULL,
Customer_id TEXT NOT NULL,
Cart_id TEXT NOT NULL,
total_amount REAL,
FOREIGN KEY (Customer_id) REFERENCES Customer(Customer_id),
FOREIGN KEY (Cart_id) REFERENCES Cart(Cart_id)
);
CREATE TABLE Product (
Product_id TEXT PRIMARY KEY NOT NULL,
Type TEXT NOT NULL,
Color TEXT NOT NULL,
P_Size TEXT NOT NULL,
Gender TEXT NOT NULL,
Commission INTEGER NOT NULL,
Cost INTEGER NOT NULL,
Quantity INTEGER NOT NULL,
Seller_id TEXT,
FOREIGN KEY (Seller_id) REFERENCES Seller(Seller_id) ON DELETE SET NULL
);
CREATE TABLE Cart_item (
Quantity_wished INTEGER NOT NULL,
Date_Added DATE NOT NULL,
Cart_id TEXT NOT NULL,
Product_id TEXT NOT NULL,
purchased TEXT DEFAULT 'NO',
PRIMARY KEY (Cart_id, Product_id),
FOREIGN KEY (Cart_id) REFERENCES Cart(Cart_id),
FOREIGN KEY (Product_id) REFERENCES Product(Product_id)
);
'''
cursor.executescript(script)
conn.commit()
conn.close()
Step 2: Installing Dependencies and Connecting to the Database
We'll need to install several dependencies to facilitate the interaction between our code and the database, as well as to integrate the LLM:
- langchain: A toolkit that aids in integrating LLMs with various applications.
- openai: The OpenAI Python package, essential for interacting with GPT models.
- langchain-openai: An extension to langchain for OpenAI-specific functionalities.
- langchain-experimental: Provides experimental features in langchain, possibly including advanced integrations and tools.
We will use the SQLDatabase toolkit provided by langchain to load the model and interface with our SQL database.
!pip install -q langchain openai langchain-openai langchain-experimental faiss-cpu
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain_openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI
from google.colab import userdata
OPENAI_API_KEY = userdata.get('OPENAI_API_KEY')
db = SQLDatabase.from_uri("sqlite:////content/sample.db")
gpt = ChatOpenAI(openai_api_key=OPENAI_API_KEY,model="gpt-3.5-turbo", temperature=0)
Step 3: Setting Up an Agent and Querying
To utilize the LLM for SQL generation, we will set up an agent executor using langchain's create_sql_agent. This agent will serve as the intermediary between our natural language prompts and the SQL database, translating our queries into executable SQL statements.
- Creating the SQL Agent: Utilize create_sql_agent to initialize our agent with the necessary configurations to interact with our e-commerce database schema.
- Executing Queries: We will use the agent's ask method to input natural language prompts. The agent will then process these prompts, generate SQL queries, and execute them against our database. The output will be the result of these queries, demonstrating the LLM's ability to interact with SQL databases.
We will use the SQLDatabase toolkit provided by langchain to load the model and interface with our SQL database.
toolkit = SQLDatabaseToolkit(db=db, llm=gpt)
agent_executor = create_sql_agent(
llm=gpt,
toolkit=toolkit,
verbose=True,
agent_type="openai-tools",
)
question = "what is the cart amount for customer with customer id cid101"
agent_executor.run(question)
Logs
Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with `{}`
Cart, Cart_item, Customer, Payment, Product, Seller, Seller_Phone_num
Invoking: `sql_db_schema` with `Cart, Customer`
3 rows from Cart table:
Cart_id
crt1011
crt1012
crt1013
*/
/*
3 rows from Customer table:
Customer_id c_pass Name Address Pincode Phone_number_s Cart_id
cid100 ABCM1235 rajat G-453 632014 9893135876 crt1011
cid101 XYZ5678 john F-789 560023 9876543210 crt1012
cid102 PQRS9876 jane A-321 400001 8765432109 crt1013
*/
Invoking: `sql_db_query` with `SELECT c.Cart_id, c.Customer_id, c.Name, c.Address,
c.Pincode, c.Phone_number_s, SUM(p.Price) AS Cart_Amount FROM Customer c JOIN
Cart_item ci ON c.Cart_id = ci.Cart_id JOIN Product p ON ci.Product_id = p.Product_id
WHERE c.Customer_id = 'cid101'`
Error: (sqlite3.OperationalError) no such column: p.Price
[SQL: SELECT c.Cart_id, c.Customer_id, c.Name, c.Address, c.Pincode,
c.Phone_number_s, SUM(p.Price) AS Cart_Amount FROM Customer c JOIN Cart_item ci
ON c.Cart_id = ci.Cart_id JOIN Product p ON ci.Product_id = p.Product_id WHERE
c.Customer_id = 'cid101']
(Background on this error at: https://sqlalche.me/e/20/e3q8)
Invoking: `sql_db_schema` with `Product`
/*
3 rows from Product table:
Product_id Type Color P_Size Gender Commission Cost Quantity Seller_id
pid1001 jeans red 32 M 10 10005 20 sid100
pid1002 shirt blue L F 5 5000 15 sid101
pid1003 shoes black 40 M 8 8000 25 sid102
*/
Invoking: `sql_db_query` with `SELECT c.Cart_id, c.Customer_id, c.Name, c.Address,
c.Pincode, c.Phone_number_s, SUM(p.Cost) AS Cart_Amount FROM Customer c JOIN
Cart_item ci ON c.Cart_id = ci.Cart_id JOIN Product p ON ci.Product_id = p.Product_id
WHERE c.Customer_id = 'cid101'`
[('crt1012', 'cid101', 'john', 'F-789', 560023, 9876543210, 5000)]The cart amount
for the customer with customer id 'cid101' is 5000.
> Finished chain.
'The cart amount for the customer with customer id 'cid101' is 5000.
Coding Using a dynamic few-shot prompt
Github Link - here
Implementing a dynamic few-shot prompt involves several steps. This approach helps optimize the performance of our agent by incorporating domain-specific knowledge and context relevant to the user's input. Here's a breakdown of these steps:
Step 1: Creating Example Pairs
Firstly, we need a set of user input and corresponding SQL query examples. These examples should cover a range of typical queries related to our e-commerce schema, providing a base for the LLM to learn from.
examples = [
{"input": "List all customers.", "query": "SELECT * FROM Customer;"},
{
"input": "List all the products from a particular seller with seller_id
'sid100'",
"query": "SELECT Product.Product_id, Product.Type, Product.Color,
Product.P_Size, Product.Gender, Product.Commission, Product.Cost, Product.Quantity
FROM Product WHERE Product.Seller_id = 'sid100';",
},
{
"input": "List of all sellers with name address and their phone number",
"query": "SELECT Seller.Seller_id, Seller.Name AS Seller_Name,
Seller_Phone_num.Phone_num AS Seller_Phone_Number FROM Seller JOIN Seller_Phone_num
ON Seller.Seller_id = Seller_Phone_num.Seller_id;",
},
{
"input": "List of all the items in the cart of a customer whose Name is
'jane'",
"query": "SELECT Cart_item.Quantity_wished, Cart_item.Date_Added,
Cart_item.Cart_id, Cart_item.Product_id, Cart_item.purchased FROM Cart_item JOIN
Cart ON Cart_item.Cart_id = Cart.Cart_id JOIN Customer ON Cart.Customer_id =
Customer.Customer_id WHERE Customer.Name = 'Jane';;",
},
{
"input": "List all customers whose address is Canada.",
"query": "SELECT * FROM Customer WHERE Country = 'Canada';",
},
{
"input": "How many customers have purchased the product with Product_id
pid1002",
"query": "SELECT COUNT(DISTINCT Customer_id) AS Num_Customers_Purchased FROM
Cart_item WHERE Product_id = 'pid1002' AND purchased = 'Y'; ",
},
{
"input": "Find the total number of Products.",
"query": "SELECT COUNT(*) FROM Product;",
},
{
"input": "How many customers are there",
"query": 'SELECT COUNT(*) AS Total_Customers FROM "Customer"',
},
]
Step 2: Example Selector Creation
We then create an ExampleSelector, specifically a SemanticSimilarityExampleSelector. This selector uses semantic search to find the most relevant examples from our set based on the user's input.
- Semantic Search: The selector will analyze the semantics of the user's input and compare it with the example pairs to find the most similar ones.
- Embeddings and Vector Store: It utilizes embeddings and a vector store to perform this semantic analysis efficiently.
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY),
FAISS,
k=5,
input_keys=["input"],
)
Step 3: FewShotPromptTemplate Creation
Next, we create a FewShotPromptTemplate. This template will integrate the selected examples into a structured prompt that the LLM can understand.
- Components:
- Example Selector: Incorporates the previously created SemanticSimilarityExampleSelector.
- Example Prompt Formatting: A format for how each example should be presented within the prompt.
- Prefix and Suffix: Text to be added before and after the formatted examples to frame the prompt contextually.
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotPromptTemplate,
MessagesPlaceholder,
PromptTemplate,
SystemMessagePromptTemplate,
)
system_prefix = """You are an agent designed to interact with a SQL
database.
Given an input question, create a syntactically correct {dialect} query
to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to
obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most
interesting examples in the database.
Never query for all the columns from a specific table, only ask for the
relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools
to construct your final answer.
You MUST double check your query before executing it. If you get an
error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to
the database.
If the question does not seem related to the database, just return "I
don't know" as the answer.
Here are some examples of user inputs and their corresponding SQL
queries:"""
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=PromptTemplate.from_template(
"User input: {input}\nSQL query: {query}"
),
input_variables=["input", "dialect", "top_k"],
prefix=system_prefix,
suffix="",
)
Step 4: Constructing the Full Prompt
As we are using an OpenAI tools agent, our full prompt should be structured as a chat prompt.
- Human Message Template: This is where the user's natural language input will be placed.
- Agent Scratchpad: MessagesPlaceholder for the agent's responses and workings.
- Integration of Few-Shot Prompt: The dynamically created few-shot prompt from Step 3 will be incorporated here, providing context and examples for the agent's processing.
full_prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate(prompt=few_shot_prompt),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
]
)
# Example formatted prompt
prompt_val = full_prompt.invoke(
{
"input": "List of all sellers with name address and their phone number",
"top_k": 5,
"dialect": "SQLite",
"agent_scratchpad": [],
}
)
print(prompt_val.to_string())
agent = create_sql_agent(
llm=gpt,
db=db,
prompt=full_prompt,
verbose=True,
agent_type="openai-tools",
)
agent.invoke({"input": "List of all sellers with name address and their phone number"})
agent.invoke({"input": "List of all sellers with name address and their phone number"})
output
> Entering new AgentExecutor chain...
Invoking: `sql_db_query` with `SELECT Seller.Name, Seller.Address, Seller_Phone_num.Phone_num
FROM Seller JOIN Seller_Phone_num ON Seller.Seller_id = Seller_Phone_num.Seller_id`
[('aman', 'delhi cmc', 9943336206), ('sara', 'mumbai abc', 9876543210), ('peter', 'kolkata xyz',
8765432109), ('lisa', 'bangalore pqr', 7654321098), ('mike', 'chennai lmn', 6543210987)]Here is a list
of all sellers with their name, address, and phone number:
1. Seller Name: aman
Address: delhi cmc
Phone Number: 9943336206
2. Seller Name: sara
Address: mumbai abc
Phone Number: 9876543210
3. Seller Name: peter
Address: kolkata xyz
Phone Number: 8765432109
4. Seller Name: lisa
Address: bangalore pqr
Phone Number: 7654321098
5. Seller Name: mike
Address: chennai lmn
Phone Number: 6543210987
> Finished chain.
Conclusion
In conclusion, the integration of Large Language Models (LLMs) with SQL databases through dynamic few-shot prompting represents a significant advancement in the field of data management and natural language processing. By emulating human data analysis techniques, such as using example selectors and few-shot prompts, we can significantly enhance the accuracy and relevance of the SQL queries generated by these models. This approach not only addresses the challenges of hallucination and context window limitations but also leverages the evolving capabilities of LLMs to make data querying more intuitive and accessible for a wider range of users. As we continue to refine these methods, the potential for LLMs to revolutionize how we interact with and extract insights from vast data repositories becomes increasingly evident, paving the way for a future where complex data operations are seamlessly conducted through natural language interfaces.
Where AI meets SQL, queries transform into conversations, turning data exploration into a dialogue with knowledge itself




