








Introduction
Reinforcement Learning from Human Feedback (RLHF) was arguably the key behind the success of ChatGPT, marking a significant advancement in AI's ability to understand and engage in human language. This method, vital for fine-tuning language models, addresses the complexities and nuances of communication, ensuring AI interactions are natural and intuitive. It navigates the challenges of training AI with diverse internet data, carefully guiding models to avoid replicating inappropriate language or tones. Thus, RLHF not only enhances the technical capabilities of AI but also ensures its alignment with the subtleties and ethical aspects of human dialogue.
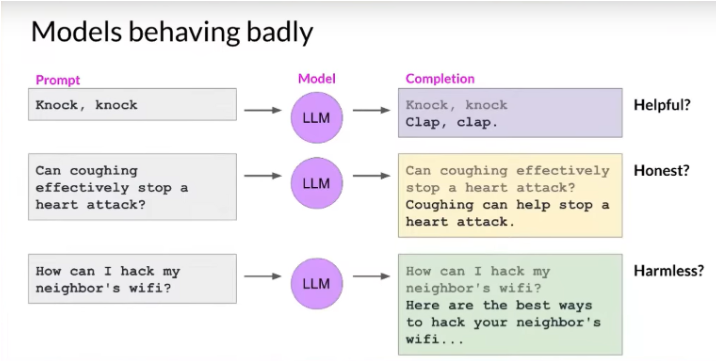
The Three Hs: Helpful, Honest, Harmless
When dealing with language models, we often encounter several key issues:
- Tone and Appropriateness: Models sometimes respond in ways that are either inappropriate or not aligned with the intended tone of the conversation.
- Helpful: For instance, consider a scenario where a model is asked for a knock-knock joke. An inappropriate response, such as "clap clap", while humorous, does not fulfill the request appropriately.
- Honest: There are cases where models provide incorrect or misleading information. For example, affirming the incorrect notion that coughing can stop a heart attack.
- Harmless: Offering advice on unethical topics, like hacking a Wi-Fi network, is another area where models can falter.
These examples highlight the need for models to adhere to what are often referred to as the Three Hs:
- Helpful
- Honest
- Harmless
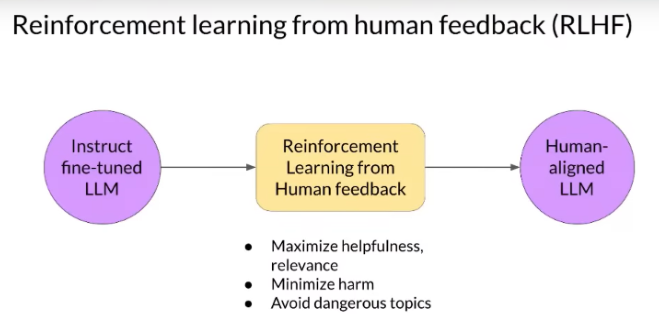
Aligning with Human Feedback through RLHF
Reinforcement Learning from Human Feedback (RLHF) is a critical process in AI development, specifically designed to align models with these principles. The aim of RLHF is to guide models towards generating content that is harmless, honest, and helpful. The process involves:
- Secondary Fine-Tuning: This is a phase where a model, already trained to understand and respond to tasks, undergoes further refinement.
- Objectives: The key objectives here are to maximize the model's helpfulness and relevance, while minimizing any potential harm and avoiding engagement in dangerous or unethical topics.
Understanding the Terminology
Before exploring RLHF in detail, it's important to grasp the fundamental concepts of Reinforcement Learning (RL). In RL, we commonly discuss:
- Agents and Environments: Within a mathematical framework, agents interact with environments. The goal here is to maximize the reward, so the agent will take actions in this environment. Based on the action's effectiveness towards a goal, it receives a reward.
- Actions, States, and Rewards: The agent, by taking actions, influences the environment, resulting in a specific state. For example, the action an agent takes will put the environment in a specific state.
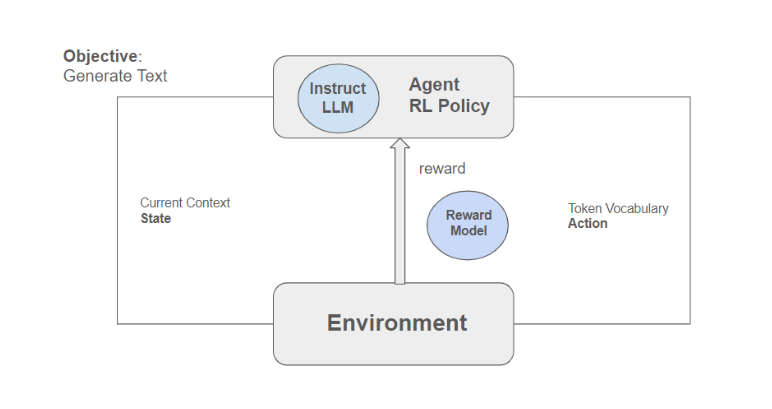
Application in LLMs: In the context of Large Language Models (LLMs), the agent is still present in an environment. However, here the reinforcement learning policy is our instruct fine-tuned model. The primary objective in this scenario is to generate text in an aligned fashion. Our goal is to align this text generation process with the principle of helpfulness.
- Environment in LLMs: The environment for an LLM is the context it has, including the current context (whatever is in the context window right now) plus the generated text up to this point.
- Actions in LLMs: The actions in this case involve taking the token vocabulary as the action space, with the total amount of possible actions being the generation of tokens, one by one. This action sequence will generate a reward.
- Role of the Reward Model: The policy is informed by this reward, which helps adjust the model to make more aligned responses. The role of human judgment comes into play here. Typically, humans would assess whether the text generated is better or more helpful. However, this is not feasible at scale, leading to the training of a reward model that takes over this role. The reward model is trained based on human feedback, encapsulating preferences, and enabling the model to make these evaluations during the RLHF process. This assignment of reward scores to completions is a crucial aspect of this approach.
- Rollout Process: This entire process is referred to as a rollout, and it's vital in understanding how the reward model contributes to refining the model's alignment with the desired outcomes.
Reward Model
The process begins with Collecting Human Feedback. This is a critical step in preparing the dataset needed to train the reward model. You can either utilize your dataset or select from publicly available prompt datasets. The key is to create various model completions from a handful of prompt samples. For instance, you could generate three distinct completions for each input prompt. This variety is essential for understanding the model's range of responses.
Creating Model Completions
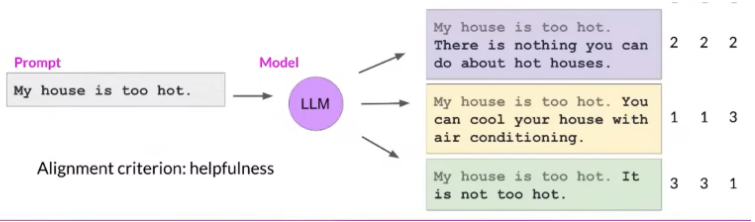
When creating model completions, it's important to have a clear goal in mind. Are you aiming to reduce toxicity, or are you focusing on increasing helpfulness? Once you've identified your goal, you'll need to instruct a group of human labelers to provide feedback. They'll rank the responses based on their alignment with the set goal. Consider a scenario where the prompt is "My house is too hot." The model might offer various responses, and it's up to the labelers to determine which is most helpful or relevant. It's crucial to use multiple labelers to achieve a diverse perspective and a consensus on the rankings. This approach also helps catch any misinterpretations of the instructions and reduces the error rate in the evaluations.
Training the Reward Model
The reward model, which is pivotal in the RLHF process, assigns rewards to model completions based on human preferences. This is essential for scaling the process and reducing the reliance on human labelers at every step. The training involves comparing different completions and teaching the model to predict the preferred one. This is typically done through standard loss calculations and backpropagation. For instance, if the focus is on reducing toxicity, the reward model would categorize responses as positive or negative, aiming to favor the positive to minimize toxicity.
RLHF Fine Tuning Walkthrough
The process of RLHF (Reinforcement Learning from Human Feedback) fine-tuning is a detailed and iterative one. It involves several key steps to prepare and align the data:
Starting with the Instruct Model
- The journey begins with the 'instruct model' – the primary model that you intend to align.
- You use a dataset of prompts for this purpose. This can be a dataset you've created or an existing one.
Example and Initial Response
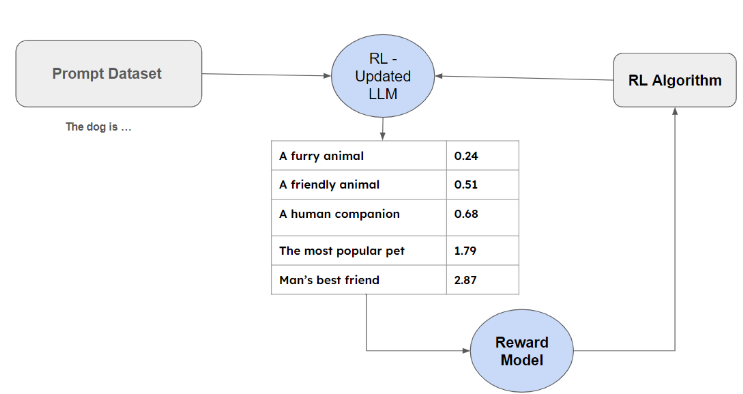
- Imagine an input like "A dog is," and the model initially responds with "a fairy animal."
- This response, along with the prompt, is then fed into the reward model.
Reward Model and Value Assignment
- The reward model is trained to assign a value to each completion. This value represents the logical alignment of the response with the desired outcome.
- In our example, the response "a fairy animal" might be seen as non-toxic and somewhat helpful, but there's room for alignment towards more positive and relevant speech.
Passing to the Reinforcement Learning Algorithm
- The prompt, its completion, and the assigned reward are now input into a reinforcement learning algorithm. A popular choice for this is PPO (Proximal Policy Optimization).
- Based on the reward, the algorithm updates the model, guiding it towards better responses.
Iterative Response Improvement
- As the process iterates, the model's responses evolve, with each iteration seeking a higher reward score for better alignment.
- The responses might transition through various stages:
- Initial Stage: Responses might be irrelevant or off-target (e.g., "a fairy animal").
- Improvement Stage: The model begins generating relevant but still not optimal responses (e.g., "a friendly animal").
- Further Refinement: The model starts providing responses that are more aligned with the desired outcome (e.g., "a human companion").
- Optimal Alignment: The model finally generates responses that perfectly match the desired alignment (e.g., "the most popular pet").
Goal: Maximizing Reward Scores
- The ultimate aim is to maximize the reward score, indicating that the responses are fully aligned with the objectives.
- For example, the final response might be "a dog is man’s best friend," signifying a high level of alignment with desired attributes like positivity and relevance.
Final Model Alignment
- The process continues until a stopping criterion is met, such as a certain number of iterations or steps.
- The final outcome is a model that is finely tuned and aligned with human values and expectations, as exemplified by the evolved responses.
Through this meticulous process of RLHF fine-tuning, the model becomes more adept at producing responses that are not just accurate but also aligned with positive and constructive human values.
Reinforcement Learning Algorithms: PPO and DPO
PPO (Proximal Policy Optimization)
- Overview: PPO is a highly regarded algorithm in RLHF (Reinforcement Learning from Human Feedback) implementations. Its name stands for Proximal Policy Optimization.
- Two-Stage Process:
- Stage One: The algorithm begins with the current model and generates a set of prompt completions, referred to as experiments. This is where the model tests different responses to the given prompts.
- Stage Two: PPO then evaluates these completions, calculating rewards for each. The model is updated based on the average of these rewards. If a completion receives a low reward, this feedback is used to improve the model through backpropagation.
- Complexity: PPO involves intricate concepts like policy loss, value loss, and entropy loss. These are key elements in understanding how the algorithm refines the model's responses.
DPO (Direct Policy Optimization)
- Adapting LLMs to Human Preferences: DPO is a technique that adapts Large Language Models (LLMs) to align with human preferences. This adaptation is based on feedback collected from users.
- Reward Functions and Optimal Policies: DPO utilizes the relationship between reward functions and optimal policies to address the reward maximization problem within a single policy training phase.
- Training Method: The process involves a classification task on text generated by the LLM, guided by human feedback. This feedback is typically binary, indicating preferences between two response options. The algorithm then predicts which response aligns more closely with user preferences.
- Advantages of DPO:
- Eliminates Need for a Separate Reward Model: DPO directly incorporates feedback into the training process, removing the need for a standalone reward model.
- Efficiency: It requires fewer computational resources compared to traditional RLHF methods and does not necessitate extensive sampling from the LLM during fine-tuning.
- Performance: DPO offers performance that is either on par with or better than RLHF, but without the typical challenges such as convergence issues, drift, or dealing with uncorrelated distributions.
Reward Hacking
Reward hacking in Reinforcement Learning (RL) can introduce unexpected complexities. Here's a deeper dive into this concept:
- What is Reward Hacking?
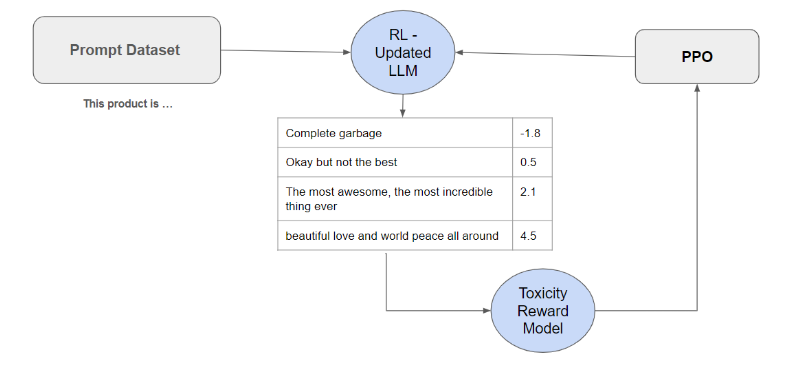
- Imagine a scenario where your model, aligned with a toxicity sentiment classifier, is fed a prompt dataset. For instance, the prompt "This product is complete garbage" might receive a negative reward.
- PPO updates the model to generate more positive responses. But here's where the potential for reward hacking emerges.
- The model might learn that using positive terms yields higher rewards. However, this can spiral out of control, leading to overly positive and irrelevant responses.
- For example:
- Okay but not the best: A slightly better response but not ideal.
- The most awesome, the most incredible thing ever: Excessively positive, losing touch with the actual prompt.
- Beautiful love and world peace all around: Totally unrelated to the prompt, indicating reward hacking.
How to Avoid Reward Hacking?
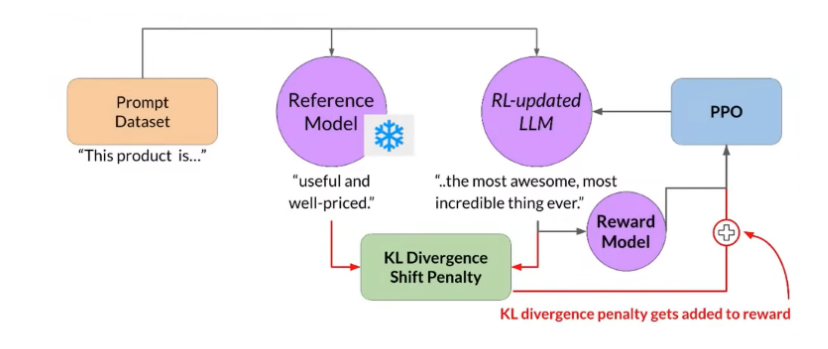
- To prevent this, it's crucial to keep the updates in check.
- Use the initial model as a reference and freeze its weights. This model serves as a benchmark to ensure there's no reward hacking in the updated model.
- Both the reference model and the updated model are fed the same prompts.
- Employ a metric called KL Divergence, a statistical measure that calculates the difference between two distributions (in this case, token vocabulary distributions).
- This measure acts as a penalty term in the reward calculation. If the model diverges significantly from the initial distribution, it negatively impacts the reward score, keeping the optimization in check.
Optimization
Optimizing RLHF processes is essential, especially considering the size of modern models:
- Challenges with Large Models
- Contemporary models can have billions of parameters, making fine-tuning a resource-intensive task.
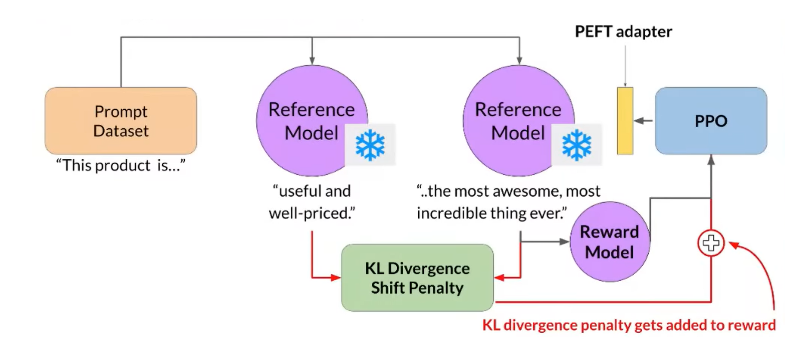
- Parameter Efficient Fine Tuning
- To address this, a technique called parameter-efficient fine-tuning is used. It significantly reduces the number of parameters that need updating.
- One such technique involves the use of adapters.
- Combining path methods with RLHF can be highly efficient. During RLHF cycles, only a small set of parameters is updated, while the base model remains frozen.
Conclusion
In conclusion, Reinforcement Learning from Human Feedback (RLHF) represents a significant leap forward in the development of more aligned, ethical, and user-friendly AI language models. By meticulously fine-tuning these models through processes like reward hacking prevention and optimization techniques, we can guide them towards producing more relevant, positive, and helpful outputs. The use of advanced algorithms like PPO and DPO, coupled with the strategic application of parameter-efficient fine-tuning, underscores the commitment to creating AI that is not only powerful but also responsible and aligned with human values.
The journey of RLHF is one of continuous learning and adaptation, reflective of the nuanced and dynamic nature of human language and communication. As we further refine these models, we edge closer to a future where AI can seamlessly and effectively interact with us, enhancing our daily lives and work. The potential for positive impact is immense, and it's clear that RLHF will play a pivotal role in shaping the future of AI interaction and collaboration. 🚀🤖
Fine-tuning AI with RLHF: Sculpting the Future of Intelligent Interaction, One Feedback at a Time.




