













Introduction
LLMs like GPT-3 or BERT are typically trained on fixed-length sequences due to practical constraints like managing computational resources and maintaining efficiency. These models, as a result, have a predetermined maximum sequence length (e.g., 512 tokens for BERT). This limitation is rooted in the self-attention mechanism, which helps the model understand and generate language by attending to contexts within this fixed length.
Positional Encoding and Its Limitations
During training, the model learns to create representations of input sequences, incorporating both content (tokens) and their positions using positional encoding. However, this training on fixed-length sequences confines the model's understanding of positional relationships within this range. Consequently, when faced with longer sequences during inference, the model encounters positions and relative distances between tokens it has never seen before.
Positional Out-of-Distribution (O.O.D.) Issues
This leads to "positional out-of-distribution (O.O.D.)" issues. Essentially, the model's performance degrades because it is processing input that is structurally different from its training data. The challenge, therefore, lies in enabling these models to handle longer sequences without encountering performance degradation due to positional O.O.D issues.
The Self-Extend Method
This method suggests a simple yet effective strategy to adapt longer 'inference time' sequences to models trained on limited context lengths without any fine-tuning. This method, called Self-Extend, proposes extending the context window of LLMs by constructing bi-level attention information: grouped attention and neighbor attention.
- Grouped Attention: Captures dependencies among tokens that are far apart by mapping large relative positions to those encountered during pretraining using a simple floor division operation.
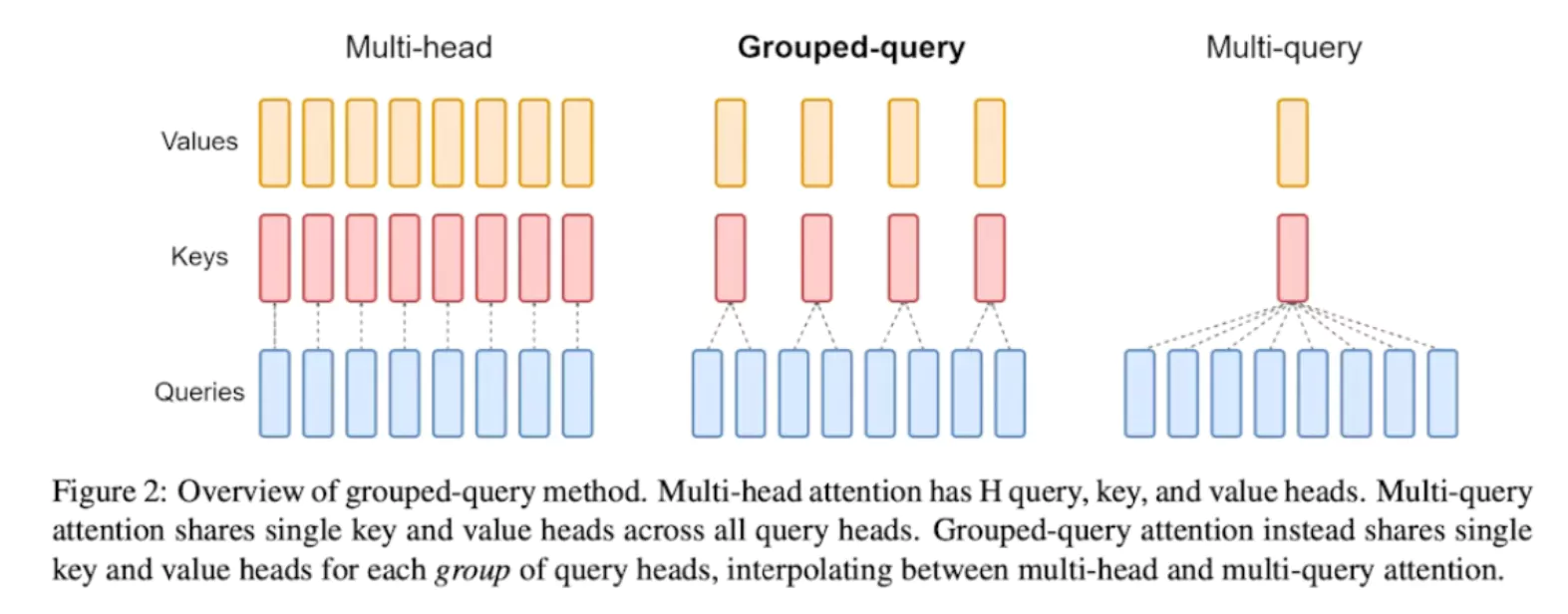
- Neighbor Attention: Retains normal attention for tokens within a specified range around each token, ensuring precise attention for the most important local contexts.
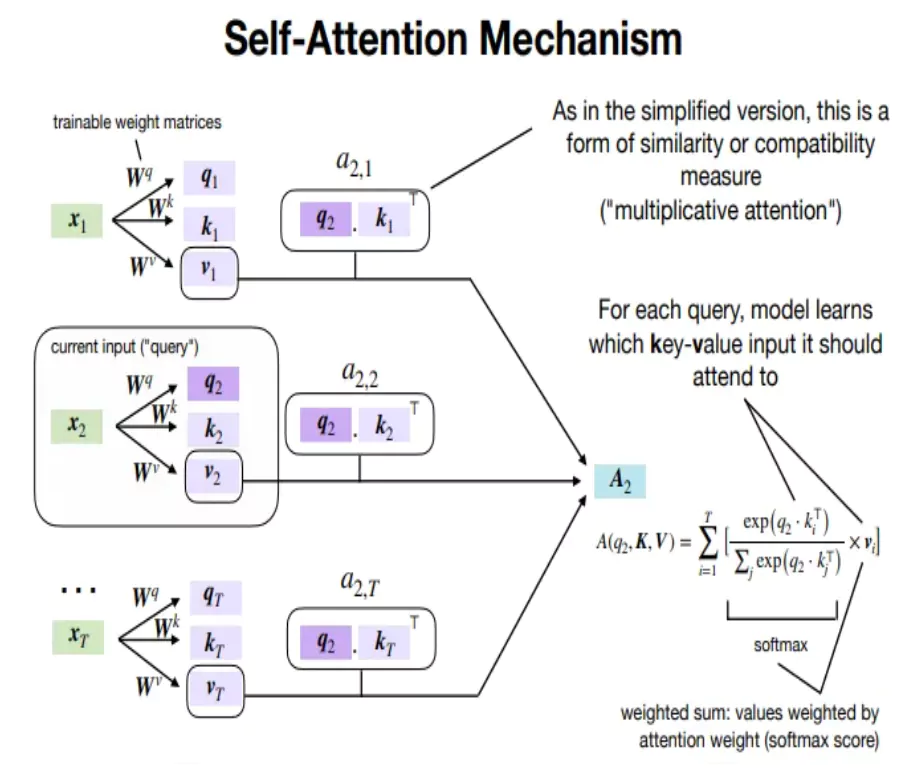
Detailed Implementation of Self-Extend
To understand how Self-Extend modifies the attention mechanism, let’s explore the process in detail.
Traditional Tokenization and Position Encoding
In traditional LLMs, the input text is tokenized, and each token is assigned a positional encoding. This helps the model understand the order of tokens, crucial for capturing syntactic and semantic relationships. For instance, consider the sentence:
"The quick brown fox jumps over the lazy dog."
Tokenized and with positional encodings, it might look like this:
[(The, 0), (quick, 1), (brown, 2), (fox, 3), (jumps, 4), (over, 5), (the, 6), (lazy, 7), (dog, 8)]
During training, the model learns to handle sequences up to a certain length (e.g., 512 tokens). When sequences exceed this length during inference, the model faces positional O.O.D (Out-Of-Distribution) issues.
Self-Extend Mechanics
- Grouped Attention: Uses floor division to map longer sequences to positions within the training range. For example, a sequence of 16 tokens with a group size of 4 maps original positions
[0, 1, 2, ..., 15]to[0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3]. This reduces positional complexity by treating groups of tokens as having the same position. - Neighbor Attention: Retains normal attention for tokens within a predefined "neighbour window" (e.g., 4 tokens). Ensures that the immediate context, crucial for local syntactic and semantic relationships, is preserved with high precision.
- Combining Grouped and Neighbour Attention: Normal attention is applied first for tokens within the neighbour window. Grouped attention is applied to tokens outside this window. The final attention matrix merges the two by replacing values outside the neighbour window with grouped attention values.
Example
Consider the tokenized sentence:
[The, quick, brown, fox, jumps, over, the, lazy, dog]
Initial Positional Encoding:
[(The, 0), (quick, 1), (brown, 2), (fox, 3), (jumps, 4), (over, 5), (the, 6), (lazy, 7), (dog, 8)]
Grouped Attention (Group Size = 3):
[(The, 0), (quick, 0), (brown, 0), (fox, 1), (jumps, 1), (over, 1), (the, 2), (lazy, 2), (dog, 2)]
Neighbor Attention (Neighbor Window = 2):
Neighbor Attention for 'fox' (Position 3): [brown (2), fox (3), jumps (4), over (5)]
Combined Attention Matrix:
Token: [The, quick, brown, fox, jumps, over, the, lazy, dog]
Position: [0, 1, 2, 3, 4, 5, 6, 7, 8]
Attention: [ N, N, N, N, N, G, G, G, G]
(N = Normal Attention, G = Grouped Attention)
Illustrative diagram
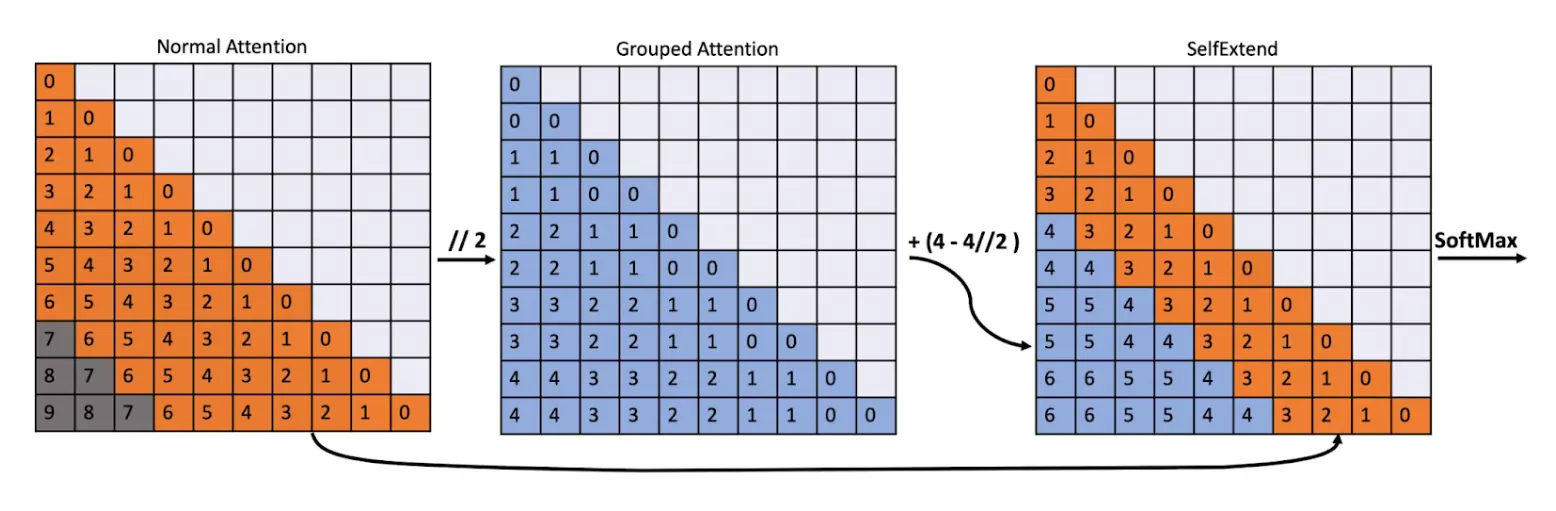
This figure illustrates the attention score matrix
(the matrix before the SoftMax operation) of the proposed Self-Extend when a sequence of length 10 is input to a LLM with a pretraining context window of length 7. The numbers represent the relative distance between the corresponding query and key tokens. Self-Extend incorporates two types of attention mechanisms: for neighbor tokens within the neighbor window, it uses the normal self-attention found in transformers; for tokens outside of this window, it utilizes values from the grouped attention. The group size is set to 2. After merging these two parts, the SoftMax operation is applied to the attention value matrix, resulting in the attention weight matrix.
Implementation Pseudo-Code
Here is a simplified pseudo-code for Self-Extend:
def self_extend_attention(q, k, v, seq_len, pos, g_size, w_size):
# Normal self-attention
ngb_q = apply_pos_encoding(q, pos)
ngb_k = apply_pos_encoding(k, pos)
ngb_attn = matmul(ngb_q, ngb_k)
ngb_attn = causal_mask(ngb_attn)
# Grouped self-attention
g_pos = pos // g_size
shift = w_size - w_size // g_size
s_g_pos = g_pos + shift
g_q = apply_pos_encoding(q, s_g_pos)
g_k = apply_pos_encoding(k, g_pos)
g_attn = matmul(g_q, g_k)
g_attn = causal_mask(g_attn)
# Merge attentions
g_mask = tril(ones([seq_len - w_size, seq_len - w_size]))
mask = ones([seq_len, seq_len])
mask[w_size:, :-w_size] -= g_mask
attn = where(mask, ngb_attn, g_attn)
attn_weights = softmax(attn)
output = matmul(attn_weights, v)
return output
The provided pseudo code for the self_extend_attention function is used in the "Final Attention Weights and Output" stage of the overall process.
Stages in the Code
- Inputs: This stage defines the input parameters such as
q, k, v, seq_len, pos, g_size,andw_size. - Normal Self-Attention:
- Positional Encoding:
ngb_qandngb_kare obtained by applying positional encoding to the query and key matrices, respectively. - Attention Scores: ngb_attn computes the attention scores by performing matrix multiplication of
ngb_qandngb_k. - Causal Mask: causal_mask is applied to ngb_attn to ensure predictions depend only on known outputs at earlier positions.
- Positional Encoding:
- Grouped Self-Attention:
- Position Calculation:
g_poscomputes the floored positions using the group sizeg_size. - Shift Calculation:
shiftadjusts positions using the window sizew_sizeand the group sizeg_size. - Positional Encoding for Grouped Attention:
g_qandg_kare calculated using adjusted positions for grouped attention. - Attention Scores for Grouped Attention:
g_attncomputes the attention scores and applies a causal mask.
- Position Calculation:
- Merging Normal and Grouped Attention:
- Mask Creation:
g_maskandmaskare created to combine normal and grouped attention scores. - Combining Attentions:
attnmerges the normal and grouped attention scores using themask.
- Mask Creation:
- Final Attention Weights and Output:
- Attention Weights:
attn_weightsare calculated by applying the SoftMax function to the combined attention scoresattn. - Final Output: The final output is computed by multiplying the attention weights
attn_weightsby the value matrixv.
- Attention Weights:
Code Implementation:
To evaluate the performance of the traditional attention mechanism versus the self-extend attention mechanism, we used the following input data:
Choose a sequence length of 100 tokens to ensure that there are ample opportunities to test the ability of the attention mechanisms to handle long-range dependencies. Each token in the sequence is represented by a 5-dimensional vector, with this dimensionality kept small for simplicity in this illustrative example.
The group size used in the self-extend mechanism for grouping tokens during attention calculation was set to 4, while the window size to determine the scope of neighbor tokens considered in normal self-attention was set to 8.
The query, key, and value matrices were initialized with random values to simulate the token embeddings.
import numpy as np
import matplotlib.pyplot as plt
# Define helper functions
def apply_pos_encoding(x, pos):
pos = pos[:, np.newaxis]
return x + pos
def matmul(a, b):
return np.dot(a, b)
def causal_mask(attn_scores):
mask = np.tril(np.ones(attn_scores.shape))
return attn_scores * mask
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
# Traditional Self-Attention Mechanism
def traditional_attention(q, k, v, seq_len, pos):
q = apply_pos_encoding(q, pos)
k = apply_pos_encoding(k, pos)
attn_scores = matmul(q, k.T)
attn_scores = causal_mask(attn_scores)
attn_weights = softmax(attn_scores)
output = matmul(attn_weights, v)
return output, attn_weights
# Updated Self-Extend Attention Mechanism
def self_extend_attention(q, k, v, seq_len, pos, g_size, w_size):
# Neighborhood attention
ngb_q = apply_pos_encoding(q, pos)
ngb_k = apply_pos_encoding(k, pos)
ngb_attn = matmul(ngb_q, k.T)
ngb_attn = causal_mask(ngb_attn)
# Grouped attention
g_pos = pos // g_size
shift = w_size - w_size // g_size
s_g_pos = g_pos + shift
g_q = apply_pos_encoding(q, s_g_pos)
g_k = apply_pos_encoding(k, g_pos)
g_attn = matmul(g_q, g_k.T)
g_attn = causal_mask(g_attn)
# Merge attention scores
g_mask = np.tril(np.ones((seq_len - w_size, seq_len - w_size)))
mask = np.ones((seq_len, seq_len))
mask[w_size:, :-w_size] -= g_mask
attn = np.where(mask, ngb_attn, g_attn)
# Calculate attention weights and output
attn_weights = softmax(attn)
output = matmul(attn_weights, v)
return output, attn_weights
# Visualization function
def plot_attention(attention_weights, title):
plt.figure(figsize=(10, 8))
plt.imshow(attention_weights, cmap='viridis')
plt.title(title)
plt.colorbar()
plt.show()
# Compute average attention distance
def compute_avg_attention_distance(attn_weights):
seq_len = attn_weights.shape[0]
distances = np.abs(np.arange(seq_len)[:, None] - np.arange(seq_len))
return np.mean(attn_weights * distances)
# Set up example input
np.random.seed(42)
seq_len = 100
d_model = 5
g_size = 4
w_size = 8
q = np.random.rand(seq_len, d_model)
k = np.random.rand(seq_len, d_model)
v = np.random.rand(seq_len, d_model)
pos = np.arange(seq_len)
# Introduce long-range dependencies
q[0, :] = q[50, :]
k[0, :] = k[50, :]
# Run traditional attention
traditional_output, trad_attn_weights = traditional_attention(q, k, v, seq_len, pos)
# Run self-extend attention
self_extend_output, self_extend_attn_weights = self_extend_attention(q, k, v, seq_len, pos, g_size, w_size)
# Compare outputs
print("Traditional Attention Output (first 5 rows):\n", traditional_output[:5])
print("\nSelf-Extend Attention Output (first 5 rows):\n", self_extend_output[:5])
# Measure difference
difference = np.linalg.norm(traditional_output - self_extend_output)
print("\nDifference between outputs:", difference)
# Visualize attention patterns
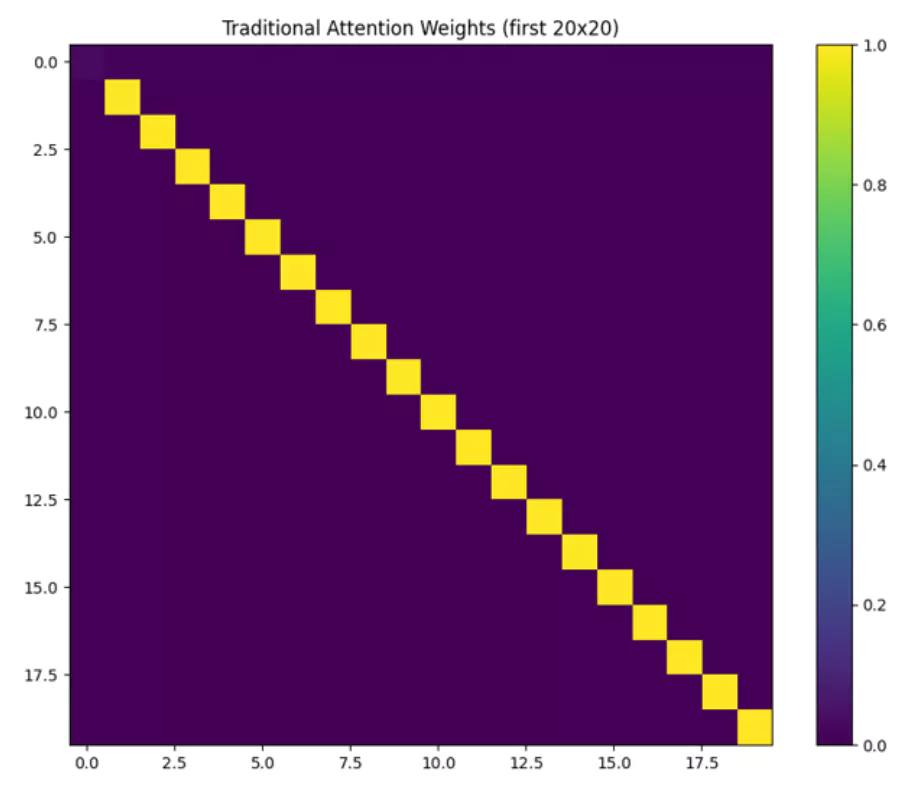
plot_attention(trad_attn_weights[:20, :20], "Traditional Attention Weights (first 20x20)")
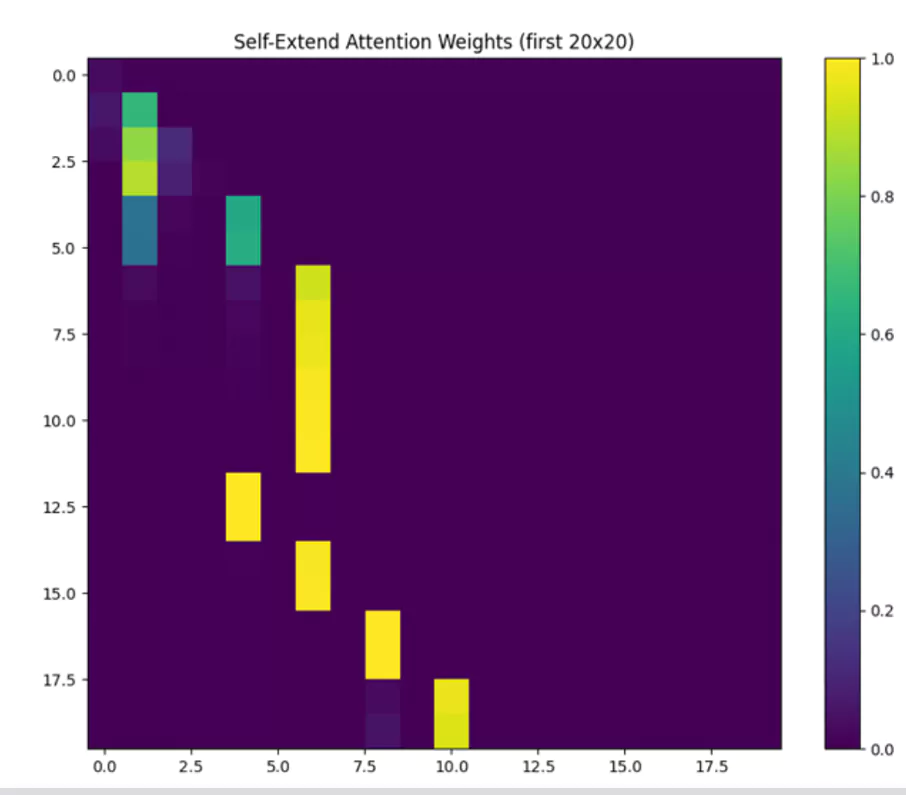
plot_attention(self_extend_attn_weights[:20, :20], "Self-Extend Attention Weights (first 20x20)")
# Compare ability to capture long-range dependencies
long_range_trad = np.corrcoef(traditional_output[0], traditional_output[50])[0, 1]
long_range_self_extend = np.corrcoef(self_extend_output[0], self_extend_output[50])[0, 1]
print(f"\nLong-range dependency correlation (Traditional): {long_range_trad:.4f}")
print(f"Long-range dependency correlation (Self-Extend): {long_range_self_extend:.4f}")
# Compute and compare average attention distances
trad_avg_distance = compute_avg_attention_distance(trad_attn_weights)
self_extend_avg_distance = compute_avg_attention_distance(self_extend_attn_weights)
print(f"\nAverage attention distance (Traditional): {trad_avg_distance:.4f}")
print(f"Average attention distance (Self-Extend): {self_extend_avg_distance:.4f}")
Output

Visualization and Analysis
The Self-Extend Attention approach, as seen from the images and metrics, tends to distribute attention more broadly across the sequence, making it potentially more suitable for tasks requiring the integration of information from different parts of a sequence. On the other hand, Traditional Attention remains highly effective for tasks where local context is crucial.
Conclusion
Self-Extend successfully extends the context window of LLMs without the need for fine-tuning. By leveraging the inherent capabilities of LLMs to handle longer texts, this method ensures that models maintain performance even with extended sequences. Self-Extend demonstrates substantial improvements in long-context tasks while preserving the ability to handle shorter texts effectively.
References:
- Hongye Jin et al., "LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning", arXiv, 2024.





