


What is image classification?
An image classification is the process by which a computer takes an input which is a picture and gives an output which could be either a class or a probability of belonging to a class. Now, the question is, how is it possible? Convolutional Neural Networks or CNN makes it possible. So what is CNN?
What is CNN?
CNN or Convolutional Neural Networks represent an interesting aspect of image processing. It is used to describe an architecture for application of neural networks to the 2D arrays which usually are images based on the spatially localized neural input. They are also called SIANN - Space Invariant Artificial Neural Networks. A wide range of applications starting from image & video recognition, recommender systems, image classification, medical image analysis, natural language processing could be seen. The motivation for this deep learning algorithm (deep neural networks) is from the biological processes representing a connectivity between neurons which resembles an organization of the animal visual cortex.
A CNN has convolutional layers, ReLU layers, pooling layers and a fully connected layers. If we compare CNN to other algorithms, they can learn filters that have to be hand-made in other such algorithms. In CNN, we would find an input layer, output layer and hidden layer. The hidden layer has convolutional layer, rectified linear unit layer, pooling layers and fully connected layers.
Another important aspect which we may discuss here is supervised machine learning before we understand how CNN works:-
Supervised machine learning is where the model is trained by giving an input data and we expect output data. To create such a model, it is necessary to go through the following steps
- Model construction
- Model training
- Model testing
- Model evaluation
These fundamental concept is well imbibed in CNN. So how does computer reads an image and how is it different from human understanding of images?
Here is a small demonstration by our engineers at Bluetick. The video shows how machine learning and artificial intelligence could be leveraged to determine some delicate intricacies of our daily life decisions.
How does computer understand images?
As humans, when we see an elephant, we understand the image and are able to classify it into a certain segment. A computer sees the picture quite differently. Instead of the image, the computer visualizes the image as an array of pixels. If the actual image size is 300x300, the array would be 300x300x3 where 300 is width, 300 is height and 3 is RGB channel values representing Red Green Blue
The computer then would assign a value from 0 to 255 to each of these numbers. The value each number carry denotes the intensity of pixel. So while we see ears and trunks, a computer sees that as a curvatures or boundaries and then it adds more abstract concepts through a group of convolutional networks.


How CNN works?
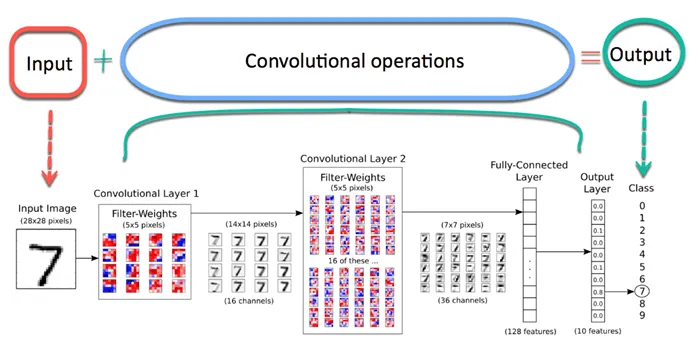
The image is passed through a series of convolutional, non-linear,
pooling layers & fully connected layers and thus it finally
generates an output.
The Convolution layer is always the first. The image (matrix with
pixel values) is entered into it. Imagine that the reading of the
input matrix begins at the top left of image. Next the software
selects a smaller matrix there, which is called a filter (or neuron,
or core). Then the filter produces convolution, i.e. moves along the
input image. The filter's task is to multiply its values by the
original pixel values. All these multiplications are summed up. One
number is obtained in the end. Since the filter has read the image
only in the upper left corner, it moves further and further right by
1 unit performing a similar operation. After passing the filter
across all positions, a matrix is obtained, but smaller than the
input matrix. The network will consist of several convolutional
networks mixed with nonlinear and pooling layers. When the image
passes through one convolution layer, the output of the first layer
becomes the input for the second layer. This happens with every such
layer and henceforth, a nonlinear layer is added after such an
operation. An activation function also adds the nonlinear property
which ensures the network has sufficient intensity and could be
model the class label as a response variable. Working with width and
height of the image ensures a down sampling operation on them and
thus the image volume is reduced Thus, it must be noted that if some
features have already been identified in the previous convolution
operation, then a detailed image is no longer needed for further
processing. Post the completion of series of convolutional,
nonlinear and pooling layers, a fully connected layer is attached
which takes the output information from the convolutional networks.
How Bluetick Consultants implemented the concept?
Here is a classic use-case of image processing using CNN done by our developers. COVID-19 pandemic has already brought in stark changes in how we live and thus every day we are adapting to this new normal. An important aspect of daily life is to wear face masks while we are outside our home. With CCTV footage, it is possible to identify whether a person is wearing mask or not and hence, we do not need human intervention to monitor.
Our engineers used Python syntax for this project. Also, we used Keras framework - a high-level neural network API written in Python and to make Keras operational, we used Google TensorFlow, a software library for backend low-level operations. We also used PyCharm as a development environment and Matplotlib for visualization.
And this happens with every further convolutional layer. The
nonlinear layer is added after each convolution operation.
We have used Image processing with face recognition and applied
segmentation for our training data applied CNN (Convolutional Neural
Network) with 2 convolution layer and 2 pooling layer with 1 flatten
layer and finally 1 output layer. We achieved the accuracy of around
94%. We have also applied data augmentation and feature scaling to
our training data so that our data would be free of noise and
training the algorithm can be more efficient and precise.









