The resume parser helps us to convert the amorphous form of resume data into a structured format. A resume parser analyses resume data and extract the most important information that automatically stores, organizes, and analyzes to find the best candidates.
For this project, we collected the data from 25 different category resumes for developing a Machine learning model to find which category the resume belongs to.
Since the data is in the unstructured format we use NLP pipeline techniques for making data into a vectorized format. Following the NLP pipeline makes us easy to develop Machine learning Models for better prediction.
Extracting the text from the resume
We build a resume parser to extract text from two different files docx and pdf files. Using the Python-docx library we extract the text when the resume is in a docx file and if the resume is in pdf format means we use the PyMuPDF library for extracting the text.
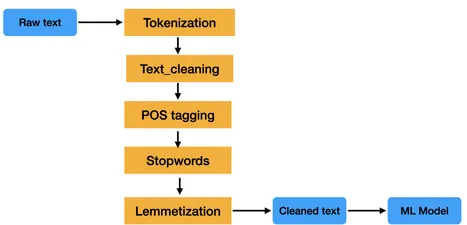
NLP Pipeline
- Word_tokenize.
- Lower the text.
- Preprocessing the text.
- Removing the stopwords.
- Lemmatization.
- Converting text into vectors.
Techniques used
- Python.
- Natural Language Processing PipeLine.
- Regex.
- Machine learning Algorithms.
- Statistics.
- Spacy.
- NLTK.
For converting the text into numerical data we implemented term frequency and inverse document frequency concept which gives importance to each word based on probability.
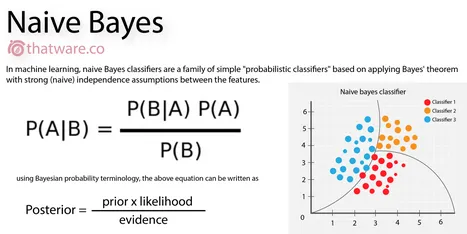
The converted numerical data were given as an input for machine learning algorithms. Since the naive Bayes works well for text data, we trained the Naive Bayes Algorithm with converted numerical data.
Since there is a small imbalance in the data we implemented upsampling techniques to overcome that process. We divide the data into 80% training and 20% testing and we got,
- Training accuracy = 0.9726918075422627
- Test accuracy = 0.9637305699481865
The ML models we developed were used to find the category of the resume to which it belongs ex: java developer, data scientist, Full stack developer.
Email address and Phone number are well-defined patterns in themselves. Thus we would be using Regular Expressions in order to capture them in the resume.
This may seem easy but in reality one of the most challenging tasks of resume parsing is to extract the person's name. There are millions of names around the world and living in a globalized world, we may come up with a resume from anywhere. For extracting the name we followed the noun concept but most of the words will fall under the noun category in the text. Mostly everyone has a first name and last name so we find the first name should be a noun and the second name should be a pronoun. By using the spacy library we got a good result on extracting the person's name.
For extracting the skills we collected the top 50 skills and using spacy matcher we mapped each word from the text with 50 skills so the words which match the condition can belong to the skills category. This technique helps us to find the skills from the resume.
Since extracting the total years of experience is too difficult we tested with multiple conditions but finally, we extract experience by finding the number with the years keyword or with a + sign.
So with the help of ML models and python, we developed a resume parser application that can extract the important information from the resume.
Example 1:
Category of Resume belongs to = Data science
------------------*--------------------
Mobile Number = ['8332812827']
-------------------*--------------------
Email = ['sandeepguthikonda95@gmail.com']
-------------------*-----------------------
Total years of experience = 5 years
-------------------*------------------------
Name = Sandeep Guthikonda
--------------------*-------------
Skills = {'machine learning', 'java', 'python', 'flask', 'deep
learning', 'natural language processing', 'django',
computervision,numpy,pandas}
Example 2:
Category of Resume belongs to = Java Developer
------------------*--------------------
Mobile Number = [' ']
-------------------*--------------------
Email = ['robertsmi@gmail.com']
-------------------*-----------------------
Total years of experience = 7 years
-------------------*------------------------
Name = Robert Smith
--------------------*-------------
Skills = {'Servlets', 'JavaBeans', 'Struts', 'Spring', 'Spring',
'JDBC', 'ODBC'}



