






Optical character recognition (OCR) is changing the way we interact with information and making it secure with the new age OCR engines.
In this blog we will try to explain what is OCR and how it is used in machine processes.
Solving problems of real world with electronic/mechanical conversion of images of typed, handwritten or printed text into machine encoded text.
In this blog we will try to explain what is OCR and how it is used in machine processes.
Also, with an example attached you'll see how, we at Bluetick Consultants extract information using OCR.
Optical character recognition using tesseract
Optical character recognition or optical character reader (OCR) is used to convert images of typed, handwritten, or printed text into machine-encoded text either electronically or mechanically. The text could be either from a scanned document, photo or from a subtitle text.
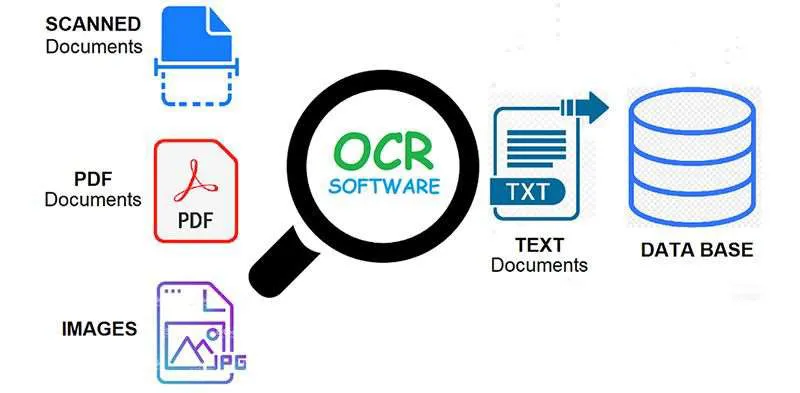
It is a very common method of digitizing printed texts so that they can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes such as cognitive computing, machine translation, text-to-speech, key data and text mining.
OCR is a field of research in pattern recognition, artificial intelligence and computer vision.
At Bluetick Consultants, we extracted important text from an image using Google OCR open source software i.e., tesseract with pytesseract
We cannot directly send an image to tesseract because it may happen that it will detect the text poorly. Therefore, we need to apply some image processing on our image in order to achieve the correct extraction of text from an image.
- We convert our image into grayscale, so that our data is compressed without the loss of information. (As we know any image consists of overlapping of 3 primary channels i.e., Red, Green and Blue. So to compress data we transform our image to grayscale so that our image contains only one channel).
- Then we apply Gaussian Blur technique in which the background of an image gets blurred and the information in the image gets enhanced. (This technique will help in detecting the text correctly by OCR).
- Then we apply some dilation and erosion on our image so that noise from an image can be removed in order to extract faulty text.
- Then we apply edge detection on our image to extract the useful information like, where the text is starting and ending or which part of the image we want to use.
- The final output image is given to tesseract which extracts the text from an image.
- We also include bounding box to an image to see whether it extracted the text from an image where the actual text is present
Note: However, the extraction of text from an image also depends upon the quality of image too.
Here is the OCR application on Aadhaar card










