





As technology becomes more advanced, we are offered privileges we could not have ever imagined and things that make our daily activities easier. Every single thing that we express has some value that can be extracted and converted into information.
Next word prediction, also referred as Language Modelling, is the process of predicting what word or multiple words come next in an application involving the basic task of typing.
We have been gradually accustomed to our mobile keyboards predicting the next word without even realizing it. Nowadays, emails and text based applications provides users with the ability to integrate this option directly.
Taking it to the next level, the data scientists at Bluetick Consultants have developed a model which predicts the next 5 words in a sentence, whenever you hit the spacebar.
Understanding Natural Language Processing
With ever increasing volume of data, it is clear that the majority of this increase is in the form of raw unstructured data. In simple terms, this means that this data cannot be organized into rows and columns or have dependencies with each other. Although thanks to AI and ML, now we have the capability to organize and process this data. The real challenge lies in understanding the meaning behind these raw words and sentences, and understanding the figures of speech like metaphors and irony or even determining the sentiment behind these illustrations. Natural Language Processing (NLP), is that branch of AI that deals with computers and human interaction using the natural language.
In order to produce significant and actionable insights from text data, to unlock the potential of text, we use NLP coupled with machine learning and deep learning.
It is known that computers and algorithms do not understand texts and characters, so it becomes essential to convert all the data in machine readable form like binary or numbers.
A wide range of applications ranging from web scraping, text to speech conversion, language translation and sentiment analysis use NLP.
There are two major components of NLP, namely Natural Language Understanding (NLU) and Natural Language Generation (NLG).
NLU helps interpret the different aspects of a language and maps them into symbolic representations whereas NLG produces meaningful sentences or phrases from these internal representations.
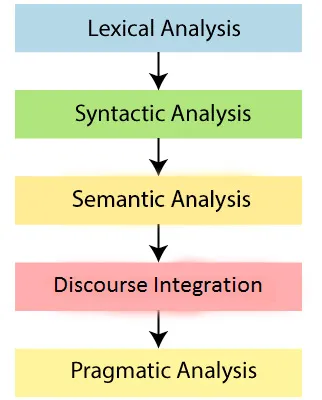
Steps used by a computer to translate the human languages
Lexical or Linguistic analysis helps in understanding the structure and meaning of the text and is then transformed into a rule based machine learning algorithm that can solve problems and complete the desired tasks.
The Syntactic analyzer identifies the dependence and relationship between the words. Any logically or naturally incorrect arrangement is rejected during syntactic processing. The sentence “ A class is taking the student.” will be rejected by the analyzer.
Breaking down a string of words into meaningful and useful parts is called tokenization. This is followed by Part of Speech Tagging (PoS) which segregates each word into noun, pronoun, verb,adverb, punctuation, adjectives etc. This helps in identifying relationships among the words and simplifies the meaning of the sentences.
The process of discourse integration has two major parts known as Dependency and Constituency Parsing.
Dependency parsing defines the grammatical structure of a sentence by listing each word as a node and attaches links to its dependents, thus forming a tree-like structure.
Discourse integration helps with the arrangement and ordering of the sentences as it interlinks the previous sentence with the current sentence. This enables in interlinking a number of sentences and deriving the complete meaning of these paragraphs.
Pragmatic analysis is the most challenging part of NLP as it involves judging the context of the statement. To take an example, the statement: “Do you know what time it is?” can be interpreted in multiple ways.
One way can be a person asking the time from another.
Another interpretation can be a parent sarcastically posing it as a rhetorical question to their child.
Engineers at Bluetick Consultants built a model which predicts the top five words.
Leveraging python and various open source libraries, our engineers swiftly implemented a working model of next top words predictor which predicts 5 words once a user hits the spacebar.
The engineering team used Flask, a web based framework which provides the relevant tools, technologies and libraries used to implement a web application. Bayesian Additive Regression Trees (BART) Model API vai the use of transformers enables the prediction of the next word. To make this operational, Google TensorFlow,a software library for backend low-level operations was used.
Firstly, the given text sentence is encoded into the tensor object using pytorch giving the ids of input text with special tokens and masking it so that our model can predict the next set of ids that are compatible with the input ids.
Then these ids are given to the BART Model so that the equivalent ids are predicted.
The equivalent ids will now be decoded and cleaned to be the next word suitable for sentence. Finally, the parameter is assigned a numerical value to predict the top 5 words that should come next in the given sentence.









